Review/Merge multiple possibles

Comments
-
Cathy Anderegg said: This is a very good suggestion. It would save tons of time.0
-
Ron Tanner said: I agree this is a good suggestion. We have actually been talking about to-do list that people could use. I think if you could mark them and have them put on your to-do list that would help you get right back to them. What do you think?0
-
Cathy Anderegg said: Yes, a To-Do List for more than just Merges is good.0
-
Sherri said: Yes, putting on a to-do list in case you are interrupted before you are finished would be a good idea. But the ability to select 5-6 possible duplicates and review one after another rather than continually going back to possible duplicates (or to a to-do list) would be a huge time saver.0
-
m said: What I wonder is if the name is somewhat common, do you ever get to the end of reviewing duplications? Example, Maria Smith0
-
Jason Ivy said: Uhm... I hope you're not merging each and every Maria Smith in FT!
(Sometimes it's hard to interpret joviality online...)0 -
m said: Actually a serious question. The high number of duplicates the computer gives you to review on common names like Maria Smith is a lot of work. I did an Anna Maria the other day and it showed me Anna Marias, Marias, other names, and every single one of her sisters who had different names and same parents. I think I did it over 4 days or something. I wonder if more will appear.0
-
Could this be expanded to do a multiple merge of all baptisms within a given period in the same place with the same abode and parents and father's occupation using a check box selection. Instead of just a table of "Our AI thinks this is a match, now you have to jump through hoops to prove it wrong" we would get a table with the actual data and a checkbox to select "Yes, these selected rows are actually the same people, please merge them into a family group" That would save hundreds of hours just for me.
1 -
@LDS Search Test , you do know how to find the Record Hints page, right?

The resulting page helps somewhat to organize the work, although there remains a lot of redundancy when there are multiple historical records for the same event.
0 -
For intensive rounds of attaching multiple duplicate historical records, I prefer the mobile app. It seems to go a lot faster and I can use more fingers in the process.
0 -
Thanks, yes, I've used that a lot, but it stops well short of what I'm asking for, which is why I'm asking for something better.
There isn't enough data in the Hint list, to make a judgement, so you have to expand it. But then to see enough information to be sure, you have to review every one of the listed items separately by loading a new page along with the ensuing delay and web traffic. I would like to see more data in the table so that it's obvious which are the same and then next to each a check box to select which are really the same people to be merged. The greatest benefit would be achieved if the child's parents were merged in the same pass.
Sometimes it's obvious that baptism / christening events are duplicated, and then again in bishop's transcripts, in which case three people in every record have to be merged. When you expand that to a large family with the same parents, it's a huge amount of work merging all the duplicates.
It would be a lot easier if so many Marriages and Baptisms had not already been assigned one-off person IDs. If they were just left unattached, then they wouldn't be duplicated. Maybe that's a way forward, go through the entire database locating person records that are only attached to a single life event with no family relationship other than that one. Then detach them and delete them. The source will still be intact but all the duplicates will be gone. By removing the need to merge so much, far fewer mistakes will occur.
0 -
Believe me, I understand the problem. Even so, I am not sure I understand what you want. Likely FT engineers don't understand either. So, could you mock up a visual of the table you want?
[...] go through the entire database locating person records that are only attached to a single life event with no family relationship other than that one.
That's why I want a tool to find all fragment trees with a person having a given surname. Another tool to deal with the hundreds of millions of duplicate PIDs resulting from early FT seeding. But so far no one has upvoted my idea:
https://community.familysearch.org/en/discussion/86291/tree-fragment-finder
0 -
@dontiknowyou I suspect the kind of procedure you're thinking of is what used to be called reconciliation(I can't imagine what it's called now), part of database integrity checking. That's supposed to be done as part of routine procedure by the administrators of the database. The trouble is that this database is big, reeally big, and the data has not been entered in a consistent fashion over time, and in many cases it is by 'untrained data entry clerks' i.e. normal folks. It is perfectly feasible, though time-consuming, to locate all errant records, and to automatically repair the damage, though I suspect it would cause adverse reaction. To inform each interested party about the reason for change might do the same, as well as overload the email server. Even so, I know that there is a great deal of behind the scenes error location and correction going on continously, because the system would have failed otherwise.
Personally I don't have anything against fragment trees as opposed to a 3 person event. Sometimes it is necessary to create one as a sandbox because there is very little evidence available, but you still need to record the group and build on it. Also, a fragment might be deliberately isolated because although the persons within it are well-documented, there might be confusing evidence that prevents it connecting to another branch. I have seen too many instances of one person being attached to 3 or more census records in the same year because the researcher could not conclude which was the correct one, ( or multiple researchers followed misleading hints.)
I suppose my argument is that duplication is OK when it impossible to be certain, in which case I usually add a line in the Life Sketch to say "This person might be the same as THX-1138" . But duplication to simply stick a person ID on a baptism or marriage is just creating more work to remove the duplication.
Regarding my earlier suggestion, As you say, it might be better to create a table to exemplify a Multiple Merge scenario, I'll have a go. I might need to create a whole bunch of tree fragments to do it, but I'll clean up afterwards.
0 -
Somethng like this...

(updated table)
You Select the rows that are to be merged, and when you click merge, you are presented with the vertical merge as is currently presented in the merge person tool, but in each section, all sets of data from the selected items in the table above are offered to the left, and none to the right. The user then drags the best data to the right. All the records are then attached to the remaining data. One person, one set of parents. I suppose there should be a method of choosing which should be the remaining ID, but that's moot. It they're all merged and attached does it really matter what the ID is.
An important thing from my point of view is being able to merge families, which would be a step up from the above, where the children of the same name and age would be merged together as themselves, but the duplicated parents of all the children would be merged into one couple.
0 -
Outline of the Merge Family idea

The intended result is to finish with ...
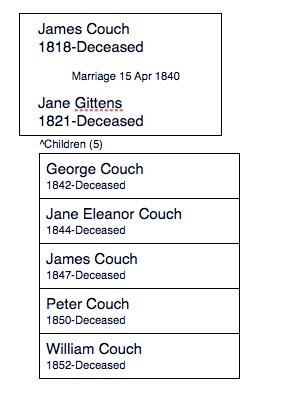
In this case, to acheive this result, a prerequisite is that the family already exists, the parents are known, and the daughter Jane Eleanor, and son James are defined, otherwise it would not be possible to merge Jane with Jane Eleanor or the person named Leuues in the baptism and the person named Thomas in the census with James born 1847.
The baptisms shown are real and are all sequential in the actual document, but for each one a new individual and a distinct set of parents was created. Thus twelve more duplicate person IDs that needed to be merged. If the records had not been attached (I presume by some automated process) then there would be no need to merge.
The corruption of names in the record is overstated on purpose with the intention of showing that even though the names do not match properly, there is ample evidence to conclude that these people are all the same family, and therefore the merge is valid.
If my presumption is correct, that the records were automatically assigned new person IDs, then a modification of that same mechanism could be used to detach them, and save work for us. I imagine this is where your proposed "Fragment Tree Finder" would be applied, but rather than do it by surname, I would just locate and detach all sources that are attached to isolated individuals, a single child + parents, or a married couple with no other family connections.
0 -
Well, I really like the objective. I too get very, very bored cleaning up the bulk seeding of Family Tree by FS.
I'm not sure I understand your thinking yet, though.
- Can you be more specific about "the family already exists, the parents are known, and the [children] are defined"?
- In your tables is the information historical records, or PIDs, or one tool for each?
- Are you thinking two tools, one to merge more than 2 PIDs in one go and another tool to assemble couples and children (aka nuclear families), or a combination multitool?
- Is this about cleaning up past bulk creation of 1-, 2- and 3-node trees by FS, or about working with records that haven't been touched yet?
Details aside, I am thinking it could work if the user had a role in selecting what goes into the table. See my next comment.
[Edit to split out the questions.]
0 -
[Edit - Updated to match the questions above]
Answer 1: In the example above, it would not have been possible for the merge to match all the people unless there was some existing information to use to make the determination. The cases of Jane Eleanor and James 1847 were deliberately made awkward to emphasize that.
The baptism data was 'massaged' to make James appear as Leuues. The merge tool would thus need to compare the family members in all the records that exist to locate anyone who is likely, just like it does when you attach a family in a census, by using name and age the existing matching code latches the person you have dragged onto an existing person or slots them in between existing ones.
The actual 1851 census record showing Thomas aged 4 is already attached to the correct person who is James 1847, and he has parents. Simlilarly, Jane Eleanor is part of the same existing family. Consequently, there is enough existing information to enable the matching algorithm to merge the children satisfactorily. If there wasn't then new children would be added to the existing family using their name and age in the record in the 'Review Merge' selection list.
Answer 2: The first table is supposed to represent items from the 'Possible Duplicates' review list but with more information shown than is the case at present. The second table is supposed to show the results from a search based on location with a given father's name. [Edit: added ->] At least one of the results in the second table must be attached to a tree, otherwise merge is not appropriate.
Answer 3: (i) The first eample 'multiple merge' is not that complicated and should be possible to create by modifying what we already have. It's an extension of the 'Review merge' list with added data and check boxes plus a change to the vertical merge layout to add more vitals and event data on the left from multiple PIDs.
(ii) The second example doesn't change the extended 'Review merge' list, but changes the level of complexity of the actual merge process. So there would be one tool, but to merge a family, the merge pages would need to be structured more like the 'review attachments' format.
(iii) I haven't thought beyond the two examples I have outlined w.r.t a 'Multitool'. If versatility is the intention, then the whole process would need to be addressed top-down with a proper requirements specification after canvassing all parties for their views. What I was hoping to promote was the least effort to a achieve the goal by using what we already have and just upping the game.
Answer 4: Yes it's primarily about cleaning up the bulk of duplicate 1-2-3 nodes and reducing the effort involved in doing so. It would also be directly applicable to any merge scenario where there are more than two duplicates. The more duplicates, the more useful it would be. I suspect that many duplicates might have have been created because the suggestion offered at 'Create New Person' time might have been the correct person, but was insufficently specific to be a safe bet. I have seen many families with children with multiple sets of parents, and others where parents have multiple children with the same name. All these could be put right if enough data is shown in the 'Review Merge' list with or without a Multiple Merge.
Further: It occurred to me only a few hours ago, that perhaps the raison-d-etre for all the pre-attached baptisms and marriages was to make the Hint tool viable. I think I'm correct in thinking that it only suggests attached records. If all the 1-2-3s were detatched then the Hints would only find people in existing trees which would dramatically reduce it's offering.
The original idea from @LegacyUser back in 2013 was asking for a way to multi-select rows from the Review Merge list then review them one by one. It was treated as a good idea at the time, but didn't make it as far as implementation. I am proposing an ammendment to provide the critical review data in the list so it can be reviewed in the list, and the selection be changed to merge the selected items in one action. I think it will save time and effort.
0 -
The hints system already does so much of this for us. What would really help, and be not a huge departure from existing systems, were the ability to aggregate the Review and Attach tasks on the Research Help page. Currently, the Research Help page exists only for PIDs.
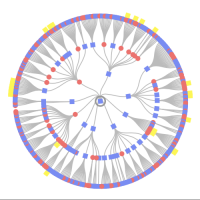
Example: https://www.familysearch.org/tree/person/research-help/G8L2-XCC
Here is a screenshot of the page as it exists now, marked up as if there were the option to attach multiple records in one step:

When the hints system finds possible duplicate records, they also appear on this page in a second block, and could perhaps be selected right along with the records. Wouldn't that be nice? That would achieve both attaching records and merging duplicate profiles in one big step.
Notice that this hypothetical multi-merge/attach operation would be per person not per family or household. Per person is how most FT tools work already, so this would not be a large departure from existing tools.
In this situation I would probably opt to not review. Instead, I would merge and attach all first, and review in the last step. Review after the merge or attachment is easy now that relevant attached sources and tagged data are displayed on the edit pop-up for each detail.
Toward that end, there is another feature I am wanting anyway in the merge process: Details not carried over are parked in the Reason statements: "Merge did not include: [insert any date, place name, reason statement from that detail on either PID that was left behind].
I could say more but probably that would be getting into the weeds.
0 -
Yep with you, but as you indicate, the Record Hints list as it currently exists doesn't have enough information in it to be certain, so you have to perform the review. Sometimes of a lot of tentative matches that turn out to be the right names in the wrong county. If the hint list had sufficient information to make the call, then you could go straight to 'attach' if the record was not yet attached, or 'merge' if it was.
Re: the snag list. I'd just presumed that the record history kept all that data anyway. I haven't actually taken the steps to record all the data in a merge before and after, then checked to see whether the change list maintained an audit trail for the rejected data.
0 -
Hypothetical attach multiple records:
- On the Record Hints page I would like Review and Attach to be separate tasks. Often I separate these two tasks by using Historical Records Search in another window to review the records at the same time as I use Record Hints to attach them.
- Separating Review and Attach would facilitate adding a feature to attach all in one fell swoop.
- Sufficient information? Use case G8L2-XCC marriage records. Information I see on the Record Hints page is enough for me to confidently attach them all to G8L2-XCC without further review.
- Sufficient information? Use case L66D-PSM screenshot below.
Weeds (important but not relevant at the moment):
- There is a problem with the G8L2-XCC records. The marriage date and place are indexed but don't propagate anywhere on FT. I had to enter them manually. That is a database problem, not a Record Hints user interface problem.
- Snag list on merges. At least now the default reasons for a merge specify the PIDs. That is a big help, but it could also generate a snag list. The audit trail isn't really adequate and after a merge I typically spend some minutes cleaning up the product PID.
- What's a snag list? See https://constructionblog.autodesk.com/construction-snag-list/

On the Record Hints page note the Show Less (Show More) button under the profile title. Very helpful!
To accomplish multi-record attachment, I suppose it would be necessary to not use the Source Linker, just do it. This would attach multiple records to one PID, rather than one record to (often) multiple PIDs.
If multi-record attachment were an option, I would still use the Source Linker in most cases but when there are many duplicate records I would attach all duplicates at once to one PID, doing each PID in turn. This is how I often work large families. Rather than working record by record, I work PID by PID:
- Choose a PID. Often I start with a child.
- Merge duplicates.
- Attach all sources.
- Finish attachment of all sources, creating new PIDs as necessary.
- Standardize dates and place names.
- Attach new sources, if any.
- Chose an attached PID (go to step 1).
- If no more PIDs remain, evaluate family for duplicates and conflations. For this I use Tree View and Timeline with Map on.
This finds more and more records without my spending any time searching for them.
0 -
Separation of Review and Attach: I support the idea to "attach all in one fell swoop" after ensuring that the data is consistent. Whether the review needs to be a separate stage is moot. That's my argument for having sufficient data in the list.
Sufficient data in the list: I have had a small number of cases where there was sufficient data shown so there must be the mechansim already, perhaps it's just fickle. In one specific case, every row of 5 in the list had exactly the same vitals, all from multiple sources that were either contemporary transcripts (like BTs) or had been processed at different times and were indexed from different films. That would have been a prime example to make the 'Merge' decision immediately. Even though this case exemplifies that all were the same, I do not propose that there should be a select all button.
In fact this merge could be done automatically provided that a critical item is included. Consider that it is possible that the records applied to two couples such as father and son or two cousins marrying women with the name first name and having two children of the same name born on the same day, and then baptised together in the same church. In such a case, without prior knowledge or a detailed study of the record to check the line number, or viewing the scan of the document, it would not be possible to determine which record applied to which child. The entry|index|line number in the record is a vital piece of information that must match. It occurs to me that data which doesn't match should be highlighted in the list. [ NOTE: I need to raise another issue connected to this about a mechanism to show the relationship between coincident baptism records i.e. many children baptised together ]
However: In the above case, I had already constructed the family as a group, and I was aware of the multiple shared names between members of the large and extended family. I was satisfied that the amassed evidence demonstrated that those 5 records were all applicable to the same child and parents. Nevertheless I still had to go round the contorted and repetetive process of merging each one separately. The process is a huge consumer of time, and at every stage there is a chance of making a mistake. i.e. failed to copy the PID when I thought I had, consequently attempted to merge Father with son. If the process is laborious and repetetive then fatigue will occur and fatigue leads to mistakes.
Multi-record attachment: This is not as complicated as multi-PID merge, so as you say, just do it, using the proposed check boxes in the Record Hints list. NOTE: The "not a match" function is good value here, it's presence could be better emphasised. It is likely that the person performing the operation has gathered valuable knowledge, it would be remiss to not promote the opportunity to collect the data that excludes the non-matches too. Perhaps the 'Review and Attach', and 'Not a Match' should both be checkboxes.
Multi-record merge: Currently the accepted method is: Locate candidate duplicate, check details, reject and find your way to get back to where you were, OR proceed, copy relevant data if necessary, confirm, finish, select view of first person again, repeat. This method creates a lot of traffic.
What I do to reduce traffic: Copy the PIDs of all targets and all duplicates into a text file, fabricate the URL to go directly to person/merge/verify for each merge case, continue, drag data, continue, enter reason, finish. The method I use avoids loading a lot of Person details Pages when I don't need to, and has saved many hours as a consequence.
Note: In the case of parents, merging the first member of a couple will always cause the relationship data to be copied, but for the the second member it more often than not has to be managed manually. This will need to be addressed in a multi-merge process, and might be managed correctly by performing the merge in a specific sequence.
Record Hints Page: The details in the known person section are not a point of contention. The details in the Data Problems Section and the Record Hints sections are the critical elements that need to be compared so they need to be present. Example screenshot.
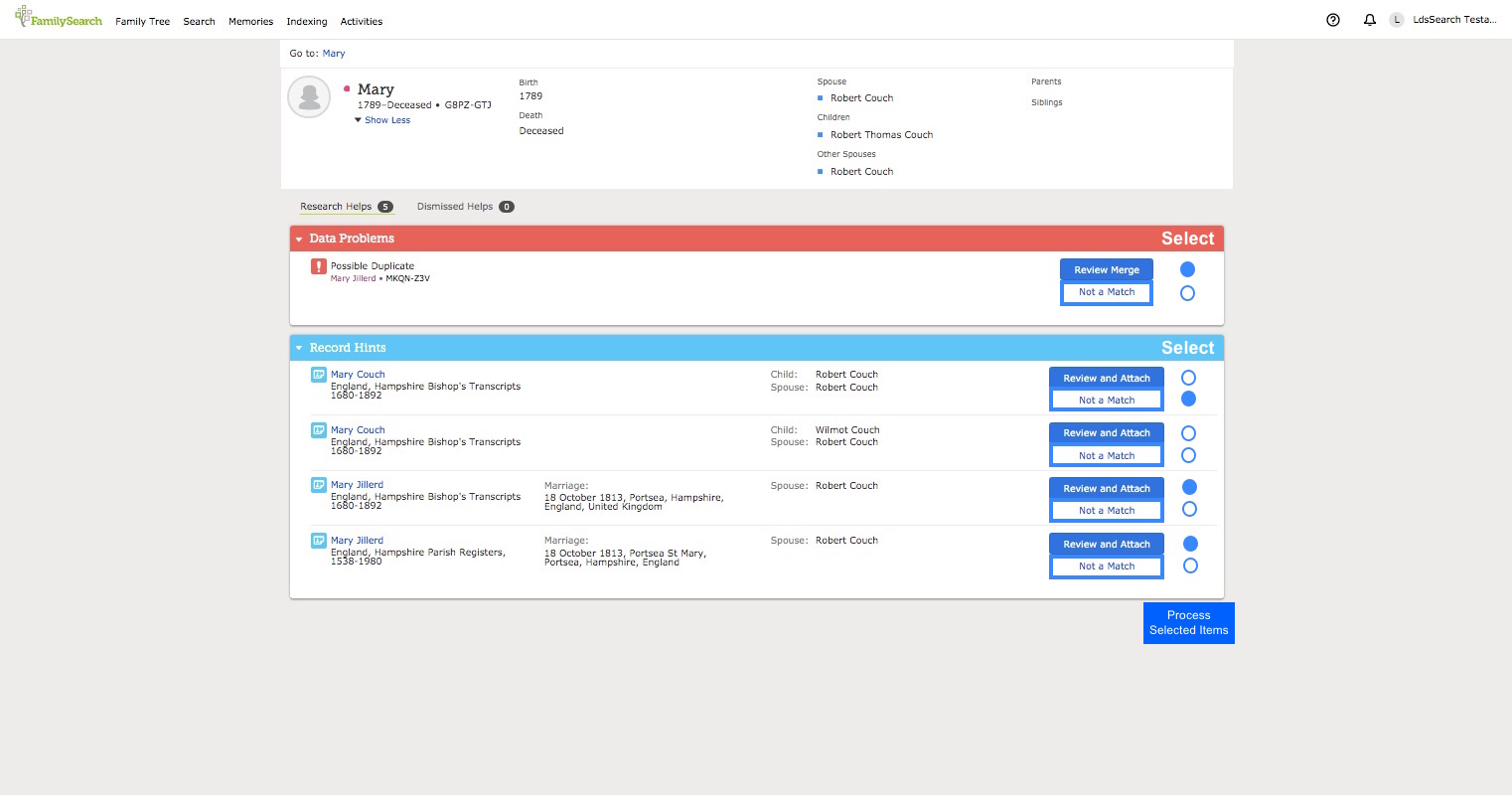
There's a lot of unused space on thge page. Perhaps in Data Problems and Record Hints sections a 'Show More' control would be beneficial to allow the important entry/index/line number to be seen.
Selection and Action
As it happens, in the example, there is only one not a match selection, so it's no huge benefit over the current procedure to just do one. You could have just selected Not a Match. If there were many, then it would be a benefit. However the objective is to round up all the activity into one procedure. The reason for the 'not a match' item being selected is not obvious, I have left it so on purpose to emphasize that the researcher already has prior knowledge that inspires them to mark that item as not a match and has chosen to do so as part of the overall activity.
When the Process Selected Items button pressed, the action would be to attach all the selected records to the focal person, attach any unattached parents/children in those records to their corresponding PIDs. As you say regarding attach, just do it. Then the action would continue by performing the merge operation using all the PIDs of the individuals in the selected rows.
It might take me while to fabricate a page that shows such a merge view. Essentially it will look just like the current /tree/person/merge/verify/THX-1138/C3PO-R2D2 arrangement except the left side will contain all the data for the PIDs and the right side will be either empty or Focal PID - moot, you can always drag dodgy data out of focal person.
Are we getting closer to a specification ?
0 -
After I suggested separating Review and Attach I had a re-think. There is actually a decision fork in the work flow here. Branch A (as-is) Review and Attach sources one by one or Branch B (proposed) Select and Attach multiple sources.
Sufficient data in the list: I have had a small number of cases where there was sufficient data shown so there must be the mechansim already, perhaps it's just fickle.
It seems to depend on the quality of indexing.
0 -
The current discussion is sort of conflating merging and attaching. This is dangerous, because people get seriously confused between Historical Records and Family Tree already.
In my part of the Tree, there are thousands upon thousands of twiglets consisting of a daughter and one or both of her parents, with all names exactly as originally indexed, and no vitals beyond the christening date and place (again, exactly as originally indexed, including weird extra commas and stuff). Yes, they're almost all daughters. I think I've encountered a grand total of three boys, and one of them was my great-grandfather who was misindexed as a girl.
The index entries that spawned these twiglets are generally offered as hints on the profiles, but are not yet attached unless some user has already done some cleanup. The hints also offer many of the girls' brothers, addable via Source Linker but not yet existing in the Tree.
Assembling a family out of this mess of twiglets and hints involves many, many steps, dozens of open tabs, and merge after tedious merge, accompanied by the constant vague worry of having missed someone somewhere. In my experience, every family has at least one person or event that has to be added manually, due to misindexing, and many families have to be very carefully sorted from other similar families. And none of it can be done based on just the indexes, because those never include things like house-numbers and godparents, which are vitally necessary to make sure they really are the same family. (I have 3ggps who shared their names with another couple living in the same small town [population less than 1300 at the time].)
I seldom need to deal with multiple indexes of the same event, thank goodness, but this means that a multi-merge tool requiring a match on the child would be of very limited utility for me. I need a multi-tool for dealing with all of the duplicate parents. To be really useful, I would need to be able to add twiglets by ID. And it would be very nice if the tool could generate a reason statement giving all of the merged IDs, along with suggested auto-text about index-based legacy profiles.
0 -
I see the same vast numbers of 3-node trees but in my case they come in 2, 3 or more sets of duplicates. For every child, a 3-tree of mother-child-father, 3 PIDs, has been created for every indexed original and copy of the child's birth, christening, and death record. Separately. Without attaching the historical record. Argh!
There is merging of PIDs and there is merging aka bulk attaching of 2+++ historical records. I am trying to maintain focus on attaching of multiple historical records, not merging PIDs. But at the same time I can see where perhaps bulk merging of PIDs could be included in the process.
It is very complicated because what if some historical records are attached already?
This hypothetical tool we are discussing would be a power tool indeed.
0 -
Am I right in thinking that when you refer to "I need a multi-tool for dealing with all of the duplicate parents" that you are describing a case where many records of a child with parents which already had PIDs are attached to the same child (either by merge or by "add parent" using ID)
If so, then I can see that the case I have described as an example would not apply to merging all those parents, unless they had some vitals in common and showed up in research hints.
In the case you describe, one child with multiple couples as parents, perhaps a solution would be a "Mark Duplicates" mechanism. Perhaps you would click "Mark Duplicates" on a person details page or a tree, then following prompts, choose a person as the one who will remain, then identify each of the multiple persons who are all actually the same person. This could then feed the relevant PIDs into a temporary "Tools - Possible Duplicates" list, which would show their vitals and relationships.
Twiglets? Is that what @dontiknowyou calls 1-2-3s ? I hadn't given them a name, just thought of them as (mostly) Event records with pre-assigned PIDs
Bulk attaching of historical records. Hmm, I hadn't realised that was your goal. Is that going to work from Search Results rather than Research Helps ? OK, I can see that some results will be attached and some won't. That would require the merger to work through the attached ones first, and merge them to other attached ones to reduce the set hopefully to one, and then attach all the remainder to that. I can see now why you were reticent about making it automatic. You really would need to review all the attached ones to clarify whether they were valid as duplicates. I notice many similar records only appear in the new layout when an event record is viewed, these same records don't show up in Research help when the person details page is viewed. That issue would preclude using the multi-merge tool previously described.
General observation
It is necessary to decide which data needs to be saved, discarded, or ammended.
Currently there is a problem with Events being atomic even though they are clearly molecular. Each comprises entities which are both elements and attributes but you can only replace the whole thing. A record with a birthplace and no date merged with a record which has a date and no place will not result in a record with both. This is already awkward when merging a person record in a baptism event which shows an exact date of birth, with data from a census event which shows an exact place of birth but only an incorrect year for birth date. To preserve the exact birthdate you must lose the exact birthplace or vice versa. The merge facility needs to allow each item in an event to be copied, discarded or collated. e.g. Birthdate from one record and birthplace from another into the focal person, or birthdate copied into the focal person, but birthplace in the focal person left untouched. In the event that the focal person's event data is null, then adding the duplicate's data should be automatic.
If that data turns out to be insufficent when another merge is conducted then it will need go through the decision mangler whether human or algorithm.
0 -
I would bulk-attach historical records from Record Hints, not pick them out of search results. Although that is a thought...
Events being a compound data type, and not carrying over, is not a concern for me. I expect to review and clean up the PID after attaching a bunch of sources. The Source Linker already drops too much data on the floor. Now that all the detail edit pages show attached sources it is much easier pick up the dropped data than to try to catch everything in the Source Linker.
0 -
I think we're still talking at cross-purposes in some parts of this discussion, so at the risk of emulating my father -- who'd start an explanation at Adam and Eve and never get as far as Noah -- I'm going to start several decades back to explain how I understand the process and situation.
Even before personal computers, Mormons were creating indexes based on church registers and other such vital records. The results of these extraction projects formed part of the International Genealogical Index.
In a predecessor system of FS's Family Tree, some parts of the IGI were turned into sets of profiles, with a new set of profiles for each indexed event, regardless of how many other events the same people may have been part of. In my corner of the world (Hungary and Slovakia), the subset that received this treatment was baptisms of girls. If parents A and B had three daughters baptized, the old system ended up with three tryptichs: {A1, 1, B1}, {A2, 2, B2}, and {A3, 3, B3}.
In other parts of the world, such as England, the IGI had separate indexes of not just the parish register, but the bishop's copy of it, and sometimes the typewritten transcription of one or both of those registers. Also in England, the creation of profiles in the old system does not seem to have been restricted to girls, meaning that a set of parents could easily end up with dozens of copies: {Ap1, p1, Bp1}, {Ab1, b1, Bb1}, {At1, t1, Bt1}, {Ap2, p2, Bp2}, {Ab2, b2, Bb2}, {At2, t2, Bt2}, {Ap3, p3, Bp3}, {Ab3, b3, Bb3}, {At3, t3, Bt3}, etc. (Also also in England, and probably other parts of the world, the IGI included indexes of marriages, not just of baptisms, further increasing the scope of the duplication.)
In 2012, all of those separate profiles were imported into Family Tree, forming thousand upon thousands of floating twiglets of mostly-duplicate profiles.
Using the current Merge process, assembling even a simple three-daughter family into one involves four merges: A1 + A2 = A, A + A3 = A, B1 + B2 = B, B + B3 = B. Each additional child adds two additional merges, each with its three steps.
What I would like in a multi-tool for merges is a way to do all of that addition in one step:
{A1, 1, B1} + {A2, 2, B2} + {A3, 3, B3} = {A, 1, 2, 3, B}
{Ap1, p1, Bp1} + {Ab1, b1, Bb1} + {At1, t1, Bt1} = {A1, 1, B1}
({Ap1, p1, Bp1}+{Ab1, b1, Bb1}+{At1, t1, Bt1}) + ({Ap2, p2, Bp2}+{Ab2, b2, Bb2}+{At2, t2, Bt2}) + ({Ap3, p3, Bp3}+{Ab3, b3, Bb3}+{At3, t3, Bt3}) = {A1, 1, B1} + {A2, 2, B2} + {A3, 3, B3} = {A, 1, 2, 3, B}
---
Separately from whatever LDS voodoo it was that turned some IGI entries into profiles, the extracted records in the IGI now form part of the vast database that one can search (with increased difficulty due to the new interface) using Search - Records. This is also the database that the Record Hints system trawls through in order to offer its suggestions. The legacy twiglets follow the IGI entries letter-for-letter, enshrining every typo, misreading, and other error, so Record Hints almost always offers up the relevant index entry. The offering can be attached to three profiles (or more) at a time, using Source Linker, either before or after combining twiglets (although it feels safer to do it before).
In parts of the world where the IGI was only partially turned into profiles, Record Hints often also finds the rest of the family, allowing one to add all the sons to go with the daughters, again using Source Linker, using its version of the Add Person dialogue.
Given that I prefer to take up Record Hints on its offers before I go about merging away the misindexed names, I'm not sure a multi-tool version of Source Linker makes sense for me.
1 -
What you outline above is inline with what I've been attempting to record as I've been performing the process. I've had a go at writing this as a kind of pidgin Pseudo Code but I can see that it might look really weird, so If you can't follow it, I understand.
Outline of Multimerge sequence
Starting from the List of Record Hints and
Collect all PIDs for focal person, immediate relatives and each person in the selected rows (assuming we can have a selection checkbox)
Focal Person Spouse Child
Focal Person M9CL-91J M9CL-913 [not set i.e. no children]
Duplicate 1 MMR8-DXW MMR8-D6K MMR8-D6S
Duplicate 2 MGXT-59L MGXT-597 MGXT-5ML
Duplicate 3 KLCL-FYH KLCL-FY4 KLCL-FYW
Duplicate 4 MGQT-KNV MGQT-KNW MGQT-KFJ
Duplicate 5 MGH7-RRL MGH7-RR8 MGH7-R5Y
Duplicate 6 MG75-D5H MG75-D5M MG75-DPF
Duplicate 7 GZLN-9F4 MV8W-44Q L1NP-1LQ
[ Merge all duplicates of the Focal Person ]
for each person in Duplicates()
Merge Duplicate(n) with focal person
Example: perform all actions in (NOTE" all these below have already been done so the links don't work)
https://www.familysearch.org/tree/person/merge/verify/M9CL-91J/MMR8-DXW
https://www.familysearch.org/tree/person/merge/verify/M9CL-91J/MGXT-59L
https://www.familysearch.org/tree/person/merge/verify/M9CL-91J/KLCL-FYH
https://www.familysearch.org/tree/person/merge/verify/M9CL-91J/MGQT-KNV
https://www.familysearch.org/tree/person/merge/verify/M9CL-91J/MGH7-RRL
https://www.familysearch.org/tree/person/merge/verify/M9CL-91J/MG75-D5H
https://www.familysearch.org/tree/person/merge/verify/M9CL-91J/GZLN-9F4
in all cases set the reason for merge to "Merged duplicate person created by (class of source) record"
[ Add Spouse or Merge duplicates of Spouse as Spouse of the Focal Person ]
for each person in Duplicates()
if spouse of Duplicate(n) exists, then
if Spouse of Focal Person exists, then
Merge spouse of duplicate(n) above with Spouse of Focal Person
Example: perform all actions in
https://www.familysearch.org/tree/person/merge/verify/M9CL-913/MMR8-D6K
https://www.familysearch.org/tree/person/merge/verify/M9CL-913/MGXT-597
https://www.familysearch.org/tree/person/merge/verify/M9CL-913/KLCL-FY4
https://www.familysearch.org/tree/person/merge/verify/M9CL-913/MGQT-KNW
https://www.familysearch.org/tree/person/merge/verify/M9CL-913/MGH7-RR8
https://www.familysearch.org/tree/person/merge/verify/M9CL-913/MG75-D5M
https://www.familysearch.org/tree/person/merge/verify/M9CL-913/MV8W-44Q
set reason for merge to "Merged duplicate person created by (class of source) record"
else
set Spouse of Focal Person to spouse of duplicate(n) ( Add new spouse )
[ Attempt to match then Add or Merge Children ]
for each person in Duplicates()
if child of Duplicate(n) exists, then
set matchingChild to null ( method of locating matching children among all children in family )
for each focalchild in Children of Couple(Focal Person and Spouse)
if Vitals of child of Duplicate(n) matches Vitals of focalchild, then
set matchingChild to PID of focalchild
if matchingChild is null
Add child of Duplicate(n) as new child of Couple(Focal Person and Spouse)
Example:
Add Child by IDNumber (MMR8-D6S)
Add Child by IDNumber (MGXT-5ML)
Add Child by IDNumber (MGQT-KFJ)
Add Child by IDNumber (MGH7-R5Y)
Add Child by IDNumber (MG75-DPF)
Add Child by IDNumber (L1NP-1LQ)
else
Merge child of Duplicate(n) with matchingChild
https://www.familysearch.org/tree/person/merge/verify/MGXT-5ML/KLCL-FYW
The Child section needs to be extended to manage multiple children of duplicates but that's not difficult. I've left it out of this outline to reduce clutter.
0