Auto Standardization

Comments
-
These are not "place-indexing errors", but yet more examples of the automated place-standardization process that has rendered FamilySearch's database completely unusable for placename-based searches.
FamilySearch, when will you finally admit that this attempt at automagically updating the database is an utter and complete failure? There are millions of these now-ridiculously-wrong entries; fixing them piecemeal, based only on the reports of users who are sufficiently motivated or savvy to figure out how, will not get to the end of it before the next century at the soonest.
All automated place-standardizations need to be reverted and a new process designed, employing proper data validation that notices, for example, that an index of Ohio deaths should not have any places of death in Iowa.
6 -
@Julia Szent-Györgyi I spent some time with our standardization team recently and wanted to share some of the things they shared with me. When we made the decision to automatically standardize locations, we made that decision knowing that there would be lots of errors. We had a huge backlog of locations that needed to be curated and at our pace at that time, it would have been to the end of the century. 😉 What that means is all those millions of unindexed records wouldn't be usable in our image search. But what we got out of automatically standardizing was worth it. For the many errors that need to be fixed, so many more unindexed records got the correct standard location. So now many millions of unindexed records are available in our image search with correct locations. None of them would have been available to our users and you would have waited years (possibly decades) for us to get all the locations correct before you could use them OR we make them all available and some have bad locations. And the other great advantage in getting these records with their bad locations in front of the users is you are helping us make corrections. We realize it's slow but are aim is make as much available to you as we possibly can. You are correct that knowing how to fix them or request them to be fixed is a bit of a mystery to most. We can do better there and they are trying to do some things that will make this easier for users. They also told me they are working on some things to correct more locations faster - but that's because they aren't spending all their time curating locations manually like they were before. I hope this helps you understand a little better. It really wasn't a failure. For many of our records it was a huge success. Now we need everyone's help to cleanup the ones that weren't a success. Sam 😊
0 -
[Mod note from Sam Sulser: I combined the threads because I had commented on a closed post. So the conversation is now here together.]
Sam replied to an older, closed thread on autostandardization errors (https://community.familysearch.org/en/discussion/comment/455205#Comment_455205). I can't reply there, so I'm starting a new thread.
We had a huge backlog of locations that needed to be curated and at our pace at that time, it would have been to the end of the century.
OK, so why not involve your users? Do a version of "improve placenames" for index entries instead of tree profiles. For many indexes, it could still be a mostly-automated batch process, with a human being just checking a single instance of a text-string-to-database-entity association: "is this an accurate interpretation of this location?"
What that means is all those millions of unindexed records wouldn't be usable in our image search. But what we got out of automatically standardizing was worth it. For the many errors that need to be fixed, so many more unindexed records got the correct standard location. So now many millions of unindexed records are available in our image search with correct locations.
Um, either you mean "indexed" when you write "unindexed", and "record" when you write "image", or you're conflating/confusing totally-unrelated things.
Going by the first interpretation (i.e., "now many millions of indexed records are available in our records search with correct locations"), I disagree: there may be some records in there that are correct, but there are also some that are wrong, so that none of it is useful. It's like mixing a cup of poisonous mushrooms into a bushel of edible ones: yes, most of them are perfectly edible, but the problem is, you can't tell which ones they are.
None of them would have been available to our users and you would have waited years (possibly decades) for us to get all the locations correct before you could use them OR we make them all available and some have bad locations.
That's "letting the best be the enemy of the good" turned inside-out: you employed a faulty process with apparently zero data validation, and are now saying that it was either that or nothing? That doesn't make any sense. Admit that the process went ridiculously awry, revert it all, and start over with a better process, one that takes existing data about collections into account, instead of letting the darts fly onto any random vaguely-matching label on the entire map.
And the other great advantage in getting these records with their bad locations in front of the users is you are helping us make corrections.
No, we're mostly not. Even those very few of us who have some idea of how to report these errors have gotten tired of the whole thing and now usually just sigh and move on: after the fifth or fifteenth example, "wow! other side of the planet!" just loses its ...novelty.
If FS really means to stick with this corruption of its database, then there needs to be an error-reporting mechanism attached to every autostandardized field.
It really wasn't a failure. For many of our records it was a huge success.
Sam, there are quite literally _millions_ of records that are so far away from "successfully standardized" that there aren't any words for it. The best that can be said about them is that at least they have the correct planet -- but only because we only live on the one.
As I said above, the autostandardization process has rendered the database completely useless for placename-based searches. You can't believe anything Search says about locations, because neither the existence nor the absence of matches says anything about where things actually took place. It would have been better at this rate to simply remove locations from the available search fields.
I'm not saying that an automated process shouldn't be used at all. With proper data validation, you could get something in the right ballpark for many indexed records. For example, if the collection in question is Ohio deaths, restrict the standardization routine for the death place field to places in Ohio. Similarly, if it's an index of parish registers from the Netherlands, don't accept burial locations in Prussia, and if it's Jewish vital registers from Hungary, don't allow birthplaces outside Austria-Hungary, or not without flagging them for human attention.
There are collections, however, where automatization is never going to work. A prime example of this is Ellis Island manifests. When it says "B.Keresztur" and "Hungary", how do you decide between Bácskeresztúr, Balatonkeresztúr, Berekeresztúr, Bethlenkeresztúr, and Bodrogkeresztúr? And that's assuming that said "B.Keresztur" wasn't unrecognizably misindexed. Collections like this must be done by human beings, and even then, there must be an option of "cannot be definitely identified, but here's the text."
1 -
I have to say I am disappointed to see that once we FINALLY get an "official" response to this long-standing problem the thread is immediately closed.
I also make note that @N Tychonievich's request that the several comments on that original post be moved to standalone posts, to facilitate review of the several issues, has apparently been ignored.
2 -
Hi Sam
I believe many of us who are "everyday" users of FamilySearch (almost literally in my case) would echo Julia's comments here. I suppose the obvious - and seemingly unkind - response to the assertion, "It really wasn't a failure. For many of our records it was a huge success", is that one would naturally expect that reaction from a team that had obviously applied considerable efforts in getting the process to work successfully. Indeed, there have been the same claims about the revised "Search" interface (and the "Find" one) producing so much improvement from the previous versions. Again, regular users will know from their everyday experiences that both these features continue to be far more difficult to deal with than their preceding models.
Please accept the word of the many who have come here to comment on such issues - especially this auto-standardization one - that these exercises have not been helpful in relation to our work on the website. Auto-standardization has led to many examples (I have encountered) going from being perfectly correct in the first place to either; (1) a wrong format (2) another place on the other side of the world or (3) something completely unexplainable (e.g. "Stockton, Norfolk" now appearing as "Hoe, Norfolk").
Another example has been in places with a correct, standard format for the period - say "Acle, Norfolk, England", pre-1801 - being changed to "Acle, Norfolk, England, United Kingdom" (the correct post-1801 format), when for years the need has been stressed to standardize place names according to that applicable to the relevant time period. Yes, on the face of it, this example may seem trivial - but not in terms of the importance FamilySearch has previously stressed on the need to us get place name formats exactly right, according to the time period.
You have to realise how much exasperation has been caused to users by this exercise. I, and I believe many others, now wonder whether there is any point in our being so precise in standardizing place names, when this factor does not seem to have been taken into account doing the programming process for this exercise.
The engineers really must accept this is one huge problem, which will take many years to put right - even if FamilySearch were to redeploy a large number of staff / volunteers to sort out the mess. Surely the users are those who should ultimately be the judge on whether, overall, this exercise has been a "success", so I believe the comments posted on this forum can speak for themselves.
Nevertheless, I thank you for your interest in this issue and hope you might continue to find time to continue to monitor the situation. As well as examining the specific examples that have been reported here, you might wish to see how many you might personally encounter during your searches.
4 -
Okay everyone, I combined the conversation into one location. I'm very sorry about the whole closed post thing. When I replied in the other conversation, I had forgotten and didn't notice that the thread was closed. That was not intentional.
Also, a quick word about how we continue this conversation. This doesn't need to turn mean. We can have an adult conversation about an issue without using unkind words and making snarky comments meant to degrade our engineers (or others) or the work they do. You really have no idea how hard they work or how hard their work is. They are people like you and me and they're trying their best to do a good job for you. It is entirely possible to express frustration and disagreement in a kind way. So, I'm asking you to kindly carry on this conversation without making degrading assumptions or mean comments.
Oh, and I'm getting more info for you around what we are doing to clean up. I'll be back shortly with another update (might be tomorrow) 🙂 Sam
0 -
A concern I have is how this looks to someone who is new to FamilySearch, doesn't have the long background many of us commenting here have in working through multiple iterations of FamilySearch databases, starting with the big binders in the Archive and Patron sections at the Library in Salt Lake and knowing through experience that things get better, they get worse, they get better, etc. We are also experienced in working down through the overlying layers of production to get to the real data.
But just picture how it looks to someone just starting out who comes to an ancestor, clicks on Show All Research Helps, and sees this:
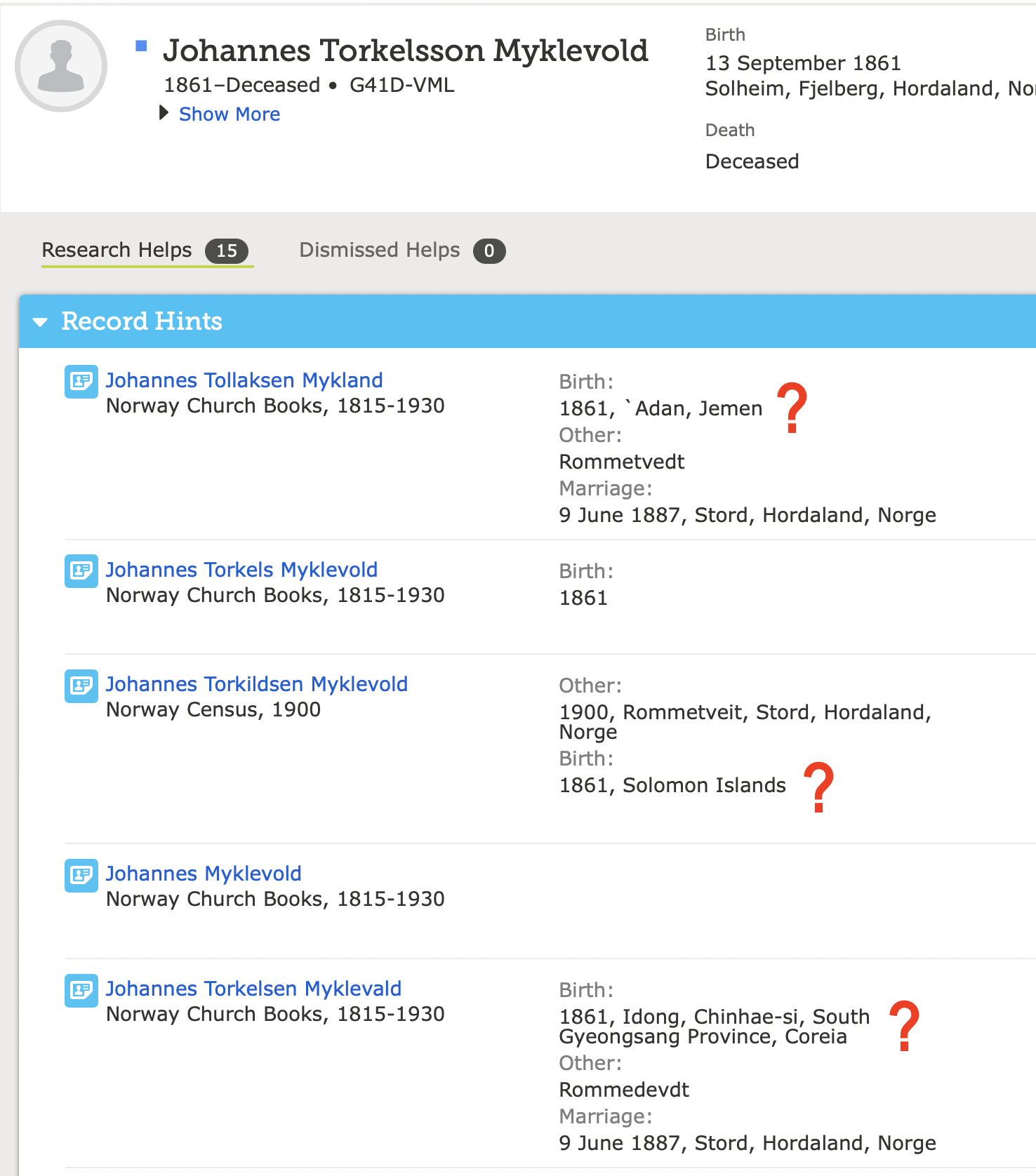
These are how:
- Myksvold I Sverin
- Sveen SB
- Myklenes I Sveen
were standardized. Looking just at the hints, I would have no idea where this man was born. If I were presented with the original place names as indexed with some transcription difficulties, I would know immediately that these all refer to Myklevold in Sveen sogn (which was in Fjelberg community) in Søndre Bergenhus, Norway.
Yes, these hints still came up correctly for this gentleman and most likely the standardized information was not used in the hint routine at all because the actual data behind it was too vague, so things do still work. But it just looks bad.
4 -
I tried to do some editing which, as usual, wrecked the image. Since it may or may not come back, here it is again:
 0
0 -
Gordon, thank you for that excellent illustration of just how badly autostandardization has corrupted the database.
FamilySearch, have the engineers seen these things? Are they aware of the absolutely ginormous scope of the problem that has been created?
4 -
@Gordon Collett Yes, it does look bad and we feel your pain more than you realize. It was not an easy decision to make. There have been multiple databases, platforms, and data formats over the decades we have been doing this. It is no wonder we have so many issues! And places are so complicated.
@Julia Szent-Györgyi Yes, the engineers have seen what Gordon shared and much more. Like I said before, this decision wasn't made without understanding the consequences and it was a difficult one to make. You may feel like we didn't really understand but we did and we do.
So as promised I have some additional info for you guys.
As I talked with one of the managers yesterday, she was very apologetic for the mess you are seeing and I wanted to pass this on to you. I know it seems like everything is just a big mess, but really it isn't, at least not everything. Yes, there are millions of records with bad standards, but there are billions that have correct standards. What was explained to me yesterday is that these changes make it much easier for us when we have to migrate data. You might say - so stop migrating data! Unfortunately, that will never be possible. We have to keep up with technology and that changes so often and so fast. So we have some fixing to do and a lot of it!
There are two teams dedicated to this work specifically. The first one spends all of their time making corrections to the database for any issues that have been reported. This is a team and not one person and this is all they do. FamilySearch has put resources toward correcting these issues that we knew would be created. Where possible they do bulk corrections. So if there is an issue with a whole group of records, they go in and fix the whole set. However, there are times where they can't do this. There are many different kinds of issues that cause the standards to be incorrect. That's where the second team comes in to play. The second team spends their time delving into the root cause of the problem. They dig deep to understand why the standards didn't work correctly. The work they do allows us to make the auto-standardizing program work better and more correctly.
What can you do? Report everything you find. That was the main message I got from the manager yesterday - after the empathy and apology! Tell us what you are seeing so we can work on it. They have a list of issues they work from and we just need to keep adding to it. When you report things here in the community, one of our support missionaries is taking that information and adding it to the issues list.
And if you'll indulge me for a bit (with time), I'm going to see what we can do to get a better reporting process. Both to report the issues to FamilySearch and to report back what has been corrected. Please understand I'm not in a position to make promises but I will work with several different teams to see what can be done. One of my goals here in the community is to communicate better with you guys! Sam 🙂
1 -
Thanks for the information.
Is there some type of standard format that would be useful in reporting problems? Should a specific category here in Communities be used to report them? Did my attempt to pass on things I have seen and to give a place for others to report such get passed on to the right people? It was here: https://community.familysearch.org/en/discussion/102829/errors-in-indexed-record-updated-place-names/p1 It got pretty long before it got closed.
3 -
> You may feel like we didn't really understand but we did and we do.
You think that you do, but I take the continued insistence on sticking with this mess and fixing it piecemeal as evidence that you really don't.
> Yes, there are millions of records with bad standards, but there are billions that have correct standards.
But you have no idea which ones are which. The only way to ensure that you're getting edible mushrooms is to sort through the entire bushel to find that cupful of poisonous ones. When "the entire bushel" means "the entire database", that's simply not possible. In other words, _it doesn't matter_ that there are correct entries in the database. The incorrect ones poison the whole lot.
> There are two teams dedicated to this work specifically.
Wouldn't all that manpower be better employed designing and implementing a better process? Instead of trying to fix the corrupted database, revert it to its previous state (you have backups, right?) and start over. If this means that we spend some time unable to restrict searches by place, so be it: it will not functionally change anything from the current state of affairs, and at least it'll be honest.
> The second team spends their time delving into the root cause of the problem.
Well, I can tell them the overarching root cause: lack of proper data validation. If the collection title starts with "Norway", why was the process allowed to choose Yemen, the Solomon Islands, and Korea? Why wasn't it restricted to, oh I don't know, maybe Norway?
> What can you do? Report everything you find.
Echoing Gordon: report everything how, and where?
3 -
@Gordon Collett If you'll notice at the top of the Search category here in Community, we have an existing issues post that is pinned to the top. The auto-standardization issue is the first on the list and it tells you that we need the URL of the record details page showing the error and gives an example of the URL. I take those and send them to engineers along with details I can find as to the extent of each error reported. (You can add more info if you'd like, but really that one URL gives me all I need to create the report).
Thank you for your desire to help us get this information to the folks who can fix things. Having one post that folks add to is OK. If you'd @ mention me when you create such a post, it'll help me spot it and get it bookmarked so I don't miss when people add to it.
1 -
@N Tychonievich, should this be a new post for each place noticed? Posted here in the Search group? (I had not seen the announcement. Early on I decided on strict limits of which Communities groups I ever look at here. I do have other projects I want to get done! And Search was not one I picked.)
I do have a few more comments and questions regarding this subject. This will be a summary and kind of repetitious of all my other posts scattered around here and there trying to help people understand what happened regarding the issues I have seen.
These auto-standardization error fall into three categories. I am wondering whether you want us to handle these differently depending on the situation and if so, what is best based on any planned thorough solution to this problem.
What I see as the common factor is that the majority of the problems have arisen due to attempting to standardized place names where the original event place as indexed contained just the smallest geographical term and no larger terms. For example, if the original event place was a single name with no other information, the routine, and I have seen no exceptions to this, simply took the first entry for that name in the Places database and used that for the new place name. For example, if a place name was indexed simply as "Columbus," typing "Columbus" in the Places database gives sixty six possible places. The auto standardization always picked the first one, so that every instance turned into "Columbus, Franklin, Ohio, United States" no matter where the place actually was.
Here are the three variations I see:
1) The same term used in one database in which there is only one accurate place for that term.
For example: "Columbus" used in a database for Nebraska. There is only one Columbus in Nebraska. If one wants to assume that if a Columbus in a different state would always have been modified in the record and then indexed as "Columbus, Other State," then the most efficient correction would be to have a new routine go through just that one database and change every Original Event Place of "Columbus" to "Columbus, Platte, Nebraska, United States"
2) A creative spelling of a place name as a one time occurrence due to either interesting spelling in a record or incorrect transcription when indexing. The correct place exists in the Places database.
For example: In my example a couple of posts up, "Myksvold I Sverin," when you look at the actual image you can see that this really should have been indexed as "Myklevold i Sveen" which would have auto-standardized fairly well to Myklevold, Sveio, Vestland, Norway. (But even this is not correct. It just happens to be the first choice in the places database. It should be Myklevold, Sveio, Hordaland, Norway, because Vestland was not created as a county until 1 January 2020.) Since Myksvold is a really bad spelling it probably does not occur anywhere else in the database and needs to be corrected as a one time action on this single record.
3) A creative spelling of a place name as a one time occurrence due to either interesting spelling in a record or incorrect transcription when indexing. The correct place does not exists in the Places database.
I don't have a specific example of this to hand, but have run into situations where I have attempted to correct an index entry by editing the place name but cannot because when I type out the full, correct place name, the error message pops up that there is no standard and the correction cannot be saved. I then have to decide whether to remove the indexed information and replace it with the standard one level up or not make the correction.
I would view the correct procedure for each of these to be:
1) Do not make any edits on the record. Report the situation so that potentially hundreds or thousands of records can be corrected at once.
2) Correct the record since this is a single occurrence of the problem. (But does this really get rid of the incorrect auto-standardization?)
3) Do not make any edits on the record. Report this with a suggestion as to what the correct standardization would be so that it can be added to the Places database and then applied to the record.
Is any of this anywhere near what you would like to have done? What do you really want us to do? Is doing random re-indexing of records by editing them one at a time in a very scattered manner going to help or actually cause more problems as a real solution is put in place?
2 -
@Gordon Collett Good questions.
When the error is a single occurrence, it is treated as an indexing error and not as an auto-standardization error. That's a whole different kind of issue. Engineers are not correcting errors indexers made that were not caught in the indexing review process. We recognize that indexes will be flawed because imperfect people created them. We ask users to edit where possible and note errors in their "attach" notes when they are not able to edit or bypass the index and attach the image itself as a source instead.
For the auto-standardization errors, it is not a problem if someone edits one of the erroneous entries. It is easy to find another right "next door" to use as an example for the engineers and it's easy to see how the place showed before editing. We actually encourage people to edit the error for their own ancestor since it can take a long time for each of these to be corrected. Their edits will not impact the fix the engineers put in place.
Yes, sometimes the Places database needs to be updated to show the correct place. If editing does not allow the correct place to be entered, suggesting the new standardization in Places becomes important.
We don't expect the users of FamilySearch to be able to read our minds and know exactly what we need when they report problems. Give us the basics and we can usually figure out the rest. If not, we will post to ask for whatever more we need.
0 -
FamilySearch is such a complicated website with so many interlocking pieces. It is so important to be precise in descriptions and to look as deep as possible at what is going on when reporting a problem because so often what looks to be the same problem is more than one.
I went to see what happened when if I tried to correct one of my Myklevold examples and found this:

The birth place which displays so badly in the hints has not been auto-standardized in the actual record. If I search for the record, the birth place displays as originally indexed. Going in to edit the index, I see the name has not been standardized, which is good because this could not be standardized correctly through any automated process.
It is only in the Hints display that the absurd standard appears. This variant of the problem seems like it would be easier to fix. Could this actually be considered a bug and the Hint display corrected so that if a place name does not have a standard applied, as here, that it would display as it does in the Search routine rather than trying to standardized it on the fly? This may correct a great proportion of the strange looking hints which is where less experienced users of Family Tree would be running into these anyway.
2 -
I, too, have often noticed that the strange place names only show up in the list view, not in the single record view. And some records from the same series show the strange place name while others show the correct location.
I noticed - again - yesterday this problem in Ireland Civil Registration (https://www.familysearch.org/search/collection/2659409) records, where 2 births in this family correctly show County Tipperary and one shows County Galway:
 1
1 -
@N Tychonievich sorry but im not seeing a pinned post to add to, the only one i can find is this thread which is closed for comments: https://community.familysearch.org/en/discussion/116253/existing-historical-records-issues#latest You mention having one post that folks add to, where is this? I can see either a one post list is going to get ridiculously long, or there will be thousands of posts created given all the problems that are now out there. South Africa and Rhodesia records alone have many hundreds of wrong placename standardisations. Is it not possible for FS to keep it simple and provide an email address, in a visible location, for everyone to use to mail in the problems? Or a feedback button on the indexed records that can be clicked there and then that links the problem placename in the image straight to the people concerned? FS seems to be getting more and more cumbersome to use and find things.
3 -
Echoing Gordon and Aine: there is definitely something funky going on in what's shown in various list views (such as results for Search - Records, or hints) and what's on the individual index entry page. It appears to me that the list view is "standardizing on the fly" -- badly -- while the index entry just shows the text field.
For example, compare this Ellis Island arrival, with a residence location indexed as "Vasashely, Hungary": https://www.familysearch.org/ark:/61903/1:1:JX1X-Q3F

with the search results page (https://www.familysearch.org/search/record/results?f.collectionId=1368704&q.anyPlace=Vasarhely) that had it as the top result:
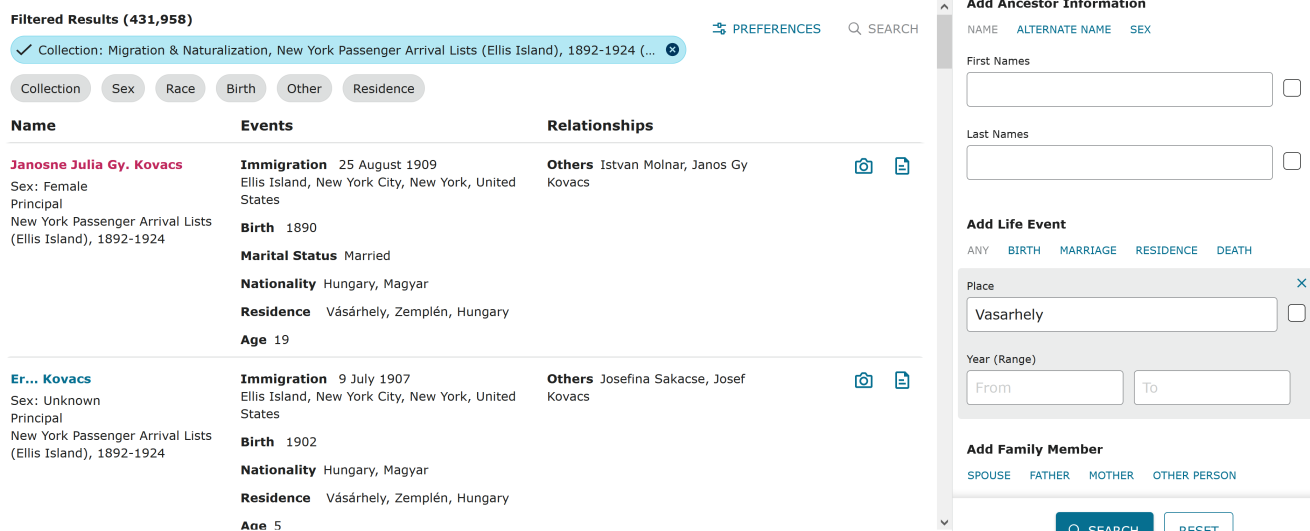
Checking the manifest, it's clear that that's the wrong Vásárhely ("market-place"; the 1913 gazetteer lists 13 of them), because the departure contact's address is the one in Torontál, not the one in Zemplén. (Torontálvásárhely was in southern Hungary and is now Debeljača, Serbia, while Zemplén-Vásárhely was in northern Hungary and is now Trhovište, Slovakia.) In fact, spot-checking the manifests for the top several search results, I couldn't find a single instance that actually meant the place in Zemplén, and none of the detail pages mention that county, and yet on the results page, it's on nearly every single entry. (The exceptions are three that were indexed as "Wasarhely, Hungary" and inexplicably display as "Granasztó, Szepes, Hungary".)
What process is making the search results list display something that isn't actually in the index, and how do we make it stop lying to us like this?
1 -
I think I can explain what has occurred in the example I posted.
The births of all 3 Maher children were registered in the Fethard registration district in County Tipperary. The birth of Bridget Maher was incorrectly indexed as Jethard, Tipperary. Some algorithm rejected Jethard as not a place, truncated the place to Cashel. There is a Cashel in County Galway. The algorithm picked that Cashel to display in the search results list.

You can see the full birth record here, on line 161. You may have to solve a Captcha to get there, but the site is free: https://civilrecords.irishgenealogy.ie/churchrecords/images/birth_returns/births_1874/03136/2149999.pdf
I can't offer an edit on FamilySearch since those records are not visible on FS, not even at an FHC, although they were once viewable at an FHC.
Note: I've edited my typo 3 times - hoping it sticks this time.
0 -
I suppose I might as well raise this example again, as yet another of the strange way place names are displayed in FamilySearch. This relates to places in Yorkshire in 1851 census records being shown on the Results page as "Cleveland, Yorkshire, England, United Kingdom".
Apart from the first entry, none of these are in the "Cleveland" area - which in itself only appears (quite correctly) as a standard place name (in the database) in the format "Cleveland, England, United Kingdom" - for the period 1974-1996. So where this "Cleveland, Yorkshire, England, United Kingdom" format comes from is quite baffling.
An example from the results page is shown below. However, as shown in the second screenshot, the name "Cleveland" is not (and never is) carried across to individual records. In this example, the event place is shown as "Attercliffe-Cum-Darnall, Yorkshire,Yorkshire (West Riding), England". (Incidentally, this would not be an acceptable format when standardizing, as the "Yorkshire (West Riding)" part is not only unrequired, but parenthesis are not allowable in standard names!
In fairness, this collection does come from Find My Past, so maybe the format / inconsistencies / errors are their responsibility. Even if so, this would show other websites also have a problem in messing-up place names!
The census area is (wrongly) shown as "Cleveland...." on the results page, but this is not carried over to individual records. Also (being a bit picky here maybe) the 1788 birthplace is shown with an incorrect (for the birth period) "United Kingdom" suffix!

 0
0 -
One of my County Tyrone, Ireland, families settled just there, so that issue resonates with me @Paul W. I don't have a great deal of English research, and I dug deep to understand the changes in place names over time in that location.
0 -
I am working with James Longstaff of FamilySearch wrt the South African Place Name Standardization. Any question wrt SA place names can be directed to me or you can join our SA Users FB Group.
0 -
When I search the family tree, the list view for ALL events in Versmold (Westphalia,) is displayed as Hartum. I think several other communities are also displayed as Hartum. But the single entry display usually shows the correct place name.
0 -
@Cheryl Viering, this is one of the times when it's important to know whether you were searching indexed historical records (Search - Records) or among Family Tree profiles (Find). The former is affected by the autostandardization mess, the latter is not. (If something is standardized incorrectly in the Tree, it's because of user error, not a bot.)
Given that Tree results do not have a "single entry display", I'm guessing that you're seeing Hartum versus Versmold in Search results, not Find results, but I cannot re-create the error either way.
1 -
This function can be reached either by 'Family Tree' / 'Find' or by 'Search' / 'Family Tree'. The results don't indicate if this is a Find or Search. A few months ago, these two actions produced different results, but they are now identical.
I am searching the Family Tree, because searching the records is worthless.
This is my latest result from the search/find.

If I click on any of the results, the events are displayed as happening in Versmold, which is the correct place.
0 -
OK, so now Find is copying Search's new habit of picking display places out of thin air. I believe this is a different problem from autostandardization, and goes back to the interface redesign (which has turned out to be a disimprovement in every respect, in my observation). The error probably needs its own thread.
2 -
Ever since Family Tree was placed as a menu option under the Search menu, it has always been just another entry point for Find under the Family Tree menu. It's just been a link to take you to the same place.
But this is strange. Searching by ID for Maria Elisabein brings her up like this:

Which displays the standardized versions of her birth and marriage information (not her displayed birth and marriage information) as expected. The usual or at least past behavior of Find is to completely ignore the displayed version of a place and only use the standardized version.
Clearly there has been an update that has changed this behavior.
Looking at Maria Elsabein's Family Tree page, you can see that her displayed Christening place is "Evangelisch,Versmold,Westfalen,Prussia."
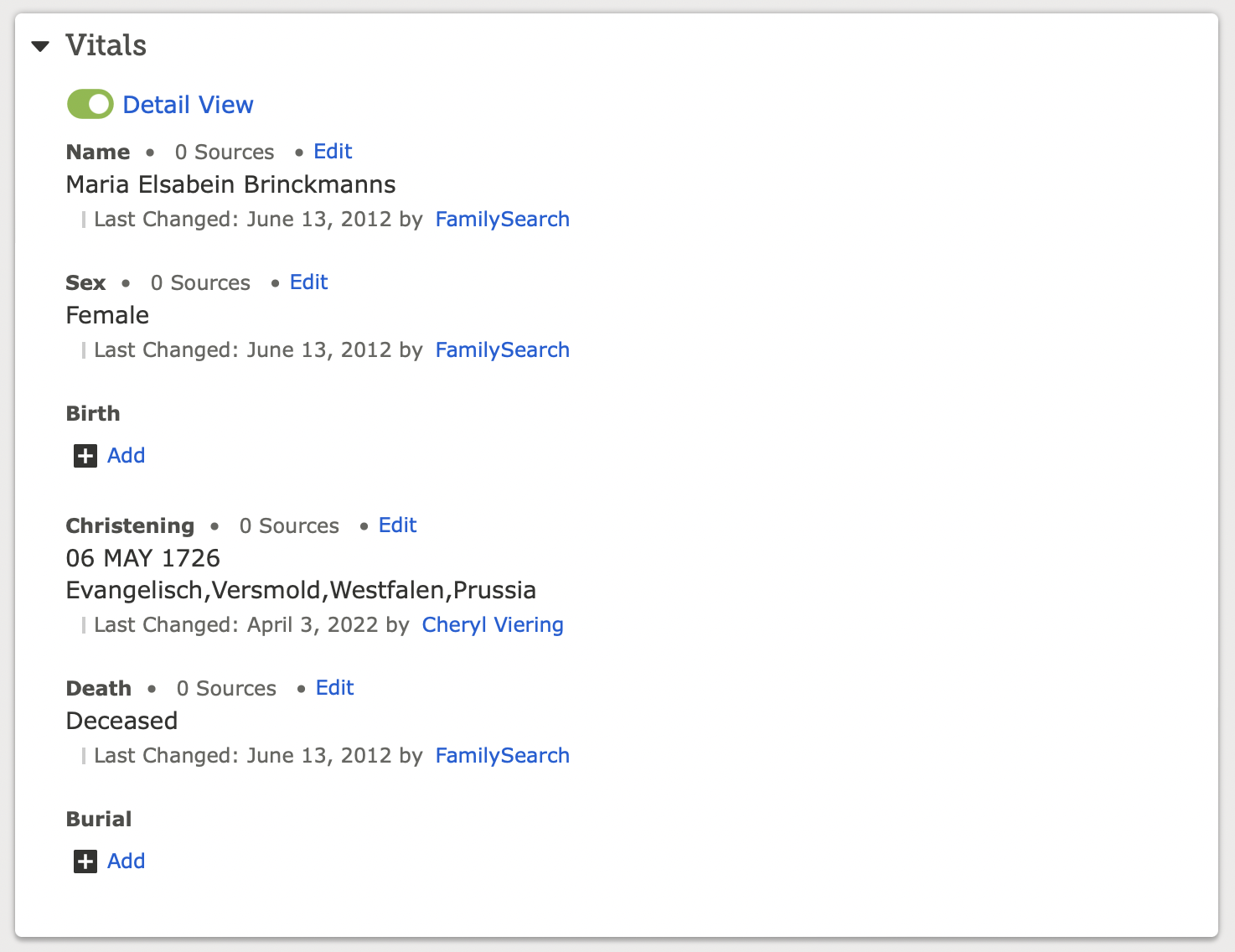
Taking that displayed version and putting it into the Places database brings up this:

The orange text shows what part of the place name as typed in is being used to match and which part is being ignored.
For some reason, the search result list is pulling in that second result and displaying it even though that is neither the displayed nor the standardized place name.
This is actually a really good problem to have posted. This is probably an update installed in both Search and Find that is the source of a lot of the result list problems in both of these and may be the key to the unexpected side effect of an update that is not working the way it was supposed to.
@Sam Sanders1 and @N Tychonievich, can you please make sure the engineers see this example of something that is going very wrong with the place name displays of both Find and Search?
1 -
@Gordon Collett Tree Find is not an area I handle. That falls to the folks who handle stuff for Family Tree. You'll have a better chance getting this to engineers if you post under the FamilySearch Help Family Tree category in Community. I'd move the discussion over there for you, but parts of it are discussing Record Search.
0 -
@gary_noble As far as one discussion where everyone posts the auto-standardization errors--that is not my personal preference. It is tedious to scroll through a zillion posts to try to find what needs to be reported. The pinned post on the Search page is for the information of our website users--to let you know what problems we are aware of. I requested that it be closed to comments to keep it clean. It is intended to be a source of information, not a place to report problems.
My preference is for you to create a new post when you want to report a problem. You can @ mention me if you'd like, but I am not the only person who gets these things handled. And I don't work 24/7, so it's not even the fastest way to get things reported. It's far better to just click FamilySearch Help and then Search and provide sufficient details that another person can replicate the problem. We have several record search support folks who are quite competent to gather the facts and get the needed information where it needs to go.
0





