Data Quality score (overly?) focused on [indexed] sources

Isabella Milner of Ingleton (1830— ?) ID: G9FK-D8L, daughter of Robinson Milner, a butcher of that place. Apparently daughter of Robinson Milner (1793—1864) ID: MNVN-RZ6 and his wife Ann née Wilson (1792—?) ID: G9FK-5S9, who were married in Staindrop, County Durham on 4 January 1819. Currently already also has her husband and children noted with no marriage event for that marriage. Birth year and place is supported by 3 sources, census of 1861 and 1871 with birth place as Ingleton, Durham and 1881 as Ingleton, Gainford. Death and burial not noted.
The Quality Score at first view is Medium.
Adding the date and place of baptism and an explanation to justify this, but no Source, causes the score to drop to Low.
This is not very encouraging at all. If the purpose is to have people work to improve sourcing, this may not work.
Comments
-
I view Family Tree as acting as a master index of all indexed historical records. In other words, when Family Tree is fully developed, one should never need to search for a person in the indexed records. Instead, one should only need to search for a person in Family Tree and when finding that person, see on that profile every indexed record pertaining to that person. This would also mean that if someone did search in the historical records, every one would be attached to a Family Tree profile. There would be no gaps as seen here:
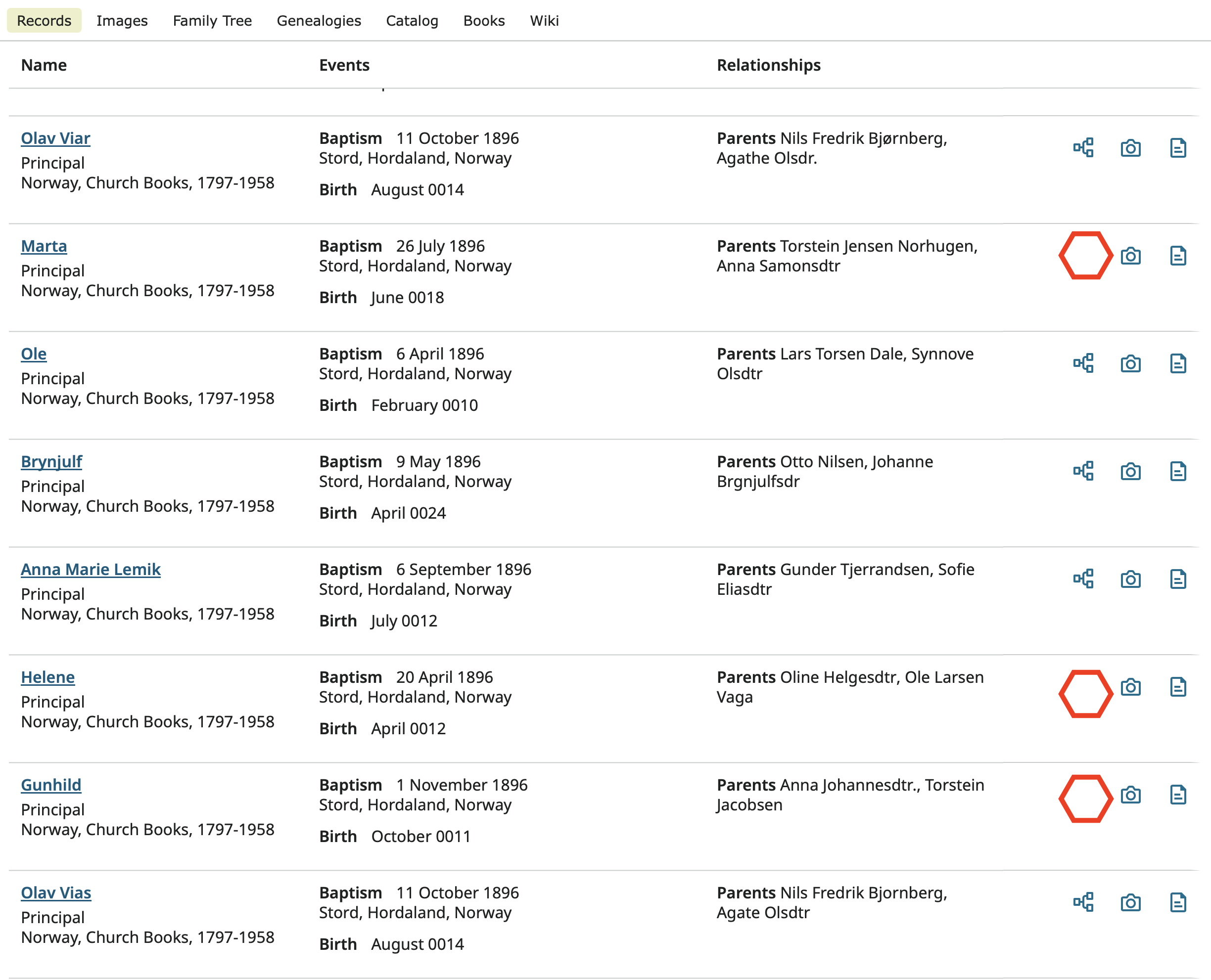
I like that the data quality score reminds us to make every effort to find indexed sources so that this master index can be completed. It's pretty simple to dismiss that reminder flag when we are positive there are no indexed sources.
But since this issue has been brought up by several users, maybe a wording change is needed. How about:
"… has no tagged indexed sources. Please attempt to find any indexed sources then attach and tag those sources as this will improve the usefulness of the historical record indexes. If there are no indexed records, you can dismiss this flag."
On a side note, I think the reason why adding the christening to Isabella dropped her quality score to low was not because of a lack of tagged sources or tagged indexed sources, but rather that the christening date of 4 March 1829 is 10 to 22 months before she was born in 1830 depending when in 1830 she was born. That causes a major non-dismissable Conflict-Free Data quality error flag.
0 -
What a depressing message especially for those with multiple indexed "sources" all referencing a single valuable original record. That source gets buried in an avalanche of indexed data.
I feel like I am from another planet. I've been active on FS for only six or seven years and I am never added an indexed source to someone's profile. The ideal goal, as I see it, is to cite an original source as evidence for every assertion made about a person. Only if original sources, or accurate images of original sources, are not available should a transcription, an extract, abstract or indexed reference to the original records be used as a source. Indexes are tools and not real sources.
For those of us with family members with dozens of indexed references based on faulty transcriptions of original documents it is doubly depressing. One original document outweighs a pile of derivative or secondary documentation.
 0
0 -
I agree that indexes are just finding aids and the original source is far more important. Which is why I think it is great that all the newer indexes are linked to the original images but which is also why I always whenever possible include a direct link to the original source and am very glad that FamilySearch puts a different icon on those direct sources:

One of the values of attaching those indexed sources that I didn't mention, is that it will prevent someone taking a possibly low quality indexed source, not understanding who the record is for, and creating a duplicate profile in Family Tree or putting the source incorrectly on a different profile.
In other words, it will prevent someone searching for a John Smith in the historical records from finding a source for my John Smith and incorrectly attaching it to his John Smith.
0 -
As far as "for those with multiple indexed 'sources' all referencing a single valuable original record. That source gets buried in an avalanche of indexed data," it is quick and easy to "un-bury" those original records. Just go to the source page, click on Options to open the side panel, and filter to see only user created sources and/or memory derived sources:
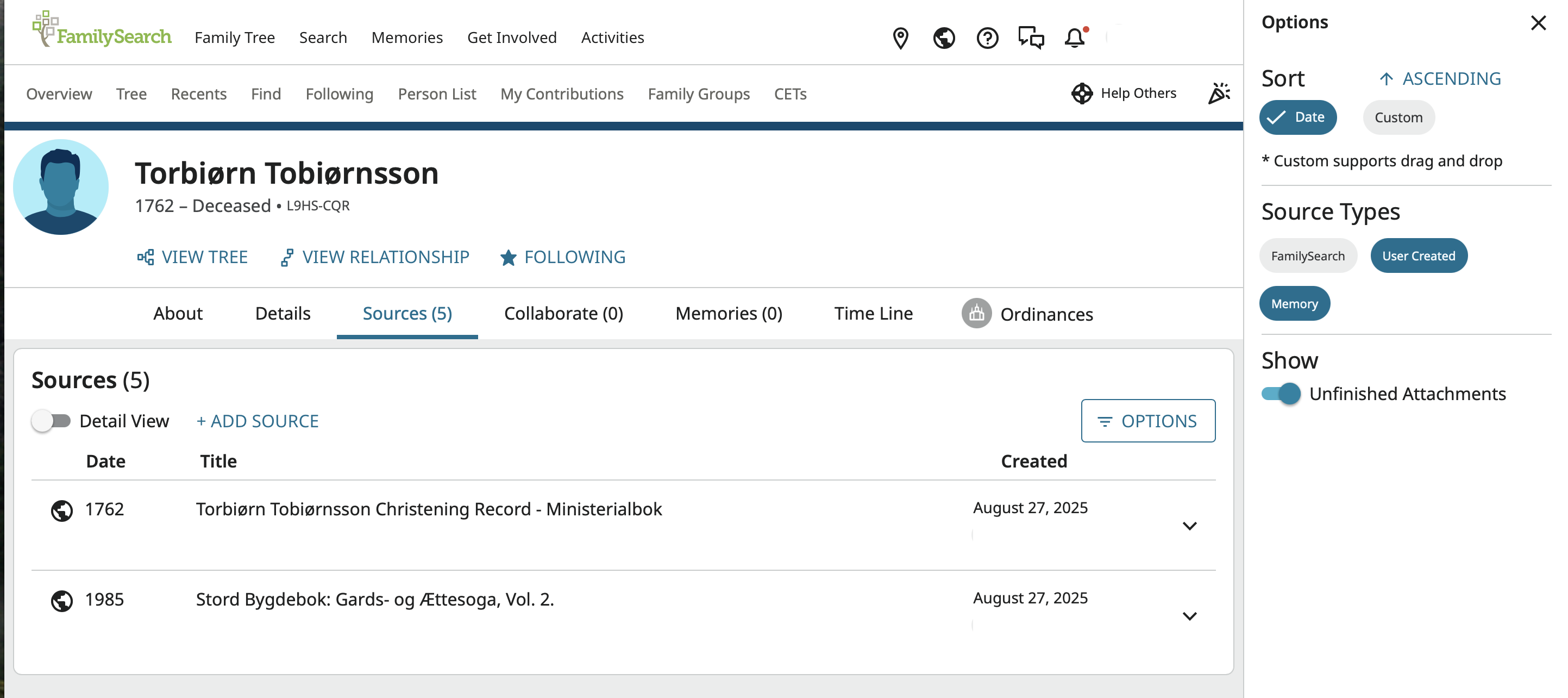 0
0 -
Certainly, attaching an index entry to a person in the tree does help to guard against it mistakenly being attached to the wrong person. And I also agree with the comment about non-indexed sources: these can potentially be worth more than a [sometimes poorly or inaccurately] indexed source.
But my post was not about the more general issue. In this case I was interested to see what would be the effect of adding a non-indexed source to the score.
A one-year difference between stated age and (calculated) birth year when dealing with the census data in England and Wales is not indicative of a problem with the quality of the data; on the contrary, it is very common. Due to a 'counting back' error, it can also apply even to the birth dates which the England and Wales 1939 Register offers. And a one year difference can also occur with age at death or burial data, depending on whether the age given is the completed age or the 'year within which' it occurred.
All of which is to say that changing the message to encourage citing a source is a good idea. But I'd go further and say that changing the score because of a one year difference in the birth is not good practice.
0 -
I can bump the score back up to Medium by adding the Bishop's Transcript for her baptism [from the (unindexed) Durham University collection available on FamilySearch] and by changing the birth date to a 'before …' date and citing the Bp Transcript as a source.
I can't find the images or an index to the parish records themselves, although microfilm (currently unindexed) of the transcriptions of these made by Kenyon-Fuller are physically available. The Kenyon-Fuller lists are freely available in digital form from other sources.
I can add the 1841 census (conveniently given as a tip), though technically it does not give relationships so it's only implicit. This has her calculated year of birth as 1829. The Quality score is now High.
The Source Consistency data is instructive (it really helps that the citations are given).The 1871/1881 censuses are out by several years and need to be checked again. It would be really helpful if one could click on the entry in the Quality Consistency comments and go to the cited index entry.
1861 is only one year out and can be ignored imho.
Census for 1841 now has the quality consistency comment: "This person has a birth date of before 4 March 1829, which does not match the date 1829." As others have said before, this is not a relevant message and can be omitted.
1 -
If I now add other members of this family, I'm struck by the absence of sources, indexed or otherwise. The reason for this is however not that the sources are not present in the FamilySearch collections; they are simply not indexed.
The baptisms for Staindrop St Mary the Virgin are in any case present in the (unindexed) transcriptions of Major Kenyon-Fuller, a microfilm of the County Durham typed version can be found in the Catalog. I cannot see this with the permissions I have working from home, but fortunately I can see a copy elsewhere.
Similarly, present but unindexed are Bishop's Transcripts for Staindrop St Mary the Virgin and again they can be linked to the family members who are found in the 1841 census for the village of Ingleton, County Durham. These can be seen, although adding them takes a bit of trouble.
Based on this, it is possible to construct the family by making new IDs, and connect the census indexes (and check images, if you have access; I do—through my own account—, and if in a FSC or affiliate I trust it will also work).
The Quality Score changes quite drastically depending on what information is added. It seems to begin at Medium even if no sources at all are given, which is a little generous for a person and Id I have just added as a child to the existing couple. Then it degrades as more detail is added if no FamilySearch indexed sources can be provided. Then it rises again if more data is added.
I suppose one could say, this is working as intended.
0 -
I'll drop out of this discussion -- my comments do not fit thepurpose of this forum. The Data Quality Score System is in its infancy and isn't able to address quality of the evidence so much as presence of an indexed source. I'll reference the profile of Joseph Hewes LCYM-ZXW. There are 15 errors in the details section of that profile. It still has a high score -- simply because there are plenty of sources. In several cases, the documents cited do not support any of the details and in some instances contradict the recorded details.
As to filtering ou tthe redundant useless sources? Joseph Haines L6SH-DFM has 163 sources. Everyone of them was created by users. The vast majority are from the Historical Soc. of Pennsylvania. HSP doesn't bother to mention their source other than their collection of extracted data.
The only relevant point I'll make is that the Data Quality Score is misnamed. Data from sources have value only when they actually provide evidence for our claims. Suppose we consider census records, church baptismal records,civil birth and death certificates to be high quality sources of data. We could attach these high quality data sources to ten random profiles and the Data Quality Score should remain constant no matter whose profile it is attached to. But in each case they would fail to provide evidence for the claims made in the profile. Evidence and data are distinct concepts.
0 -
I think that the Data Quality Score is simply testing whether the data held in an index for a source which has been attached to an entry in a person's record matches the data entered in that record. At the simplest level it's checking whether there is a cited source to begin with.
It's a very interesting idea and significantly more than most other systems at the moment. We've been asked to give feedback as users and the feedback reveals a number of issues:
- Some relevant sources are not available on the FamilySearch systems, though many are available in other ways to some users. If we self-cite, the algorithms cannot read the citation (?perhaps?) and/or determine whether the citation can be trusted.
- Some sources which are available on FamilySearch systems have remained un-indexed; we can find them here on the site and even attach them, but the citation is still liable to be treated as "no indexed sources".
- Some indexed sources have been incorrectly indexed, though if one has access to the image the index error can be ignored and correctly cited. However the Quality algorithms have no way of knowing this so will return a mismatch statement.
- Not everyone, and/or not from every location, has the requisite edit permissions to change errors in the indexes so the error will continue to be raised as a potential problem in data matching.
The Quality Score itself does not bother me personally. However, I am concerned that an incorrect score may encourage people to make changes which are not needed or not correct to "improve" the score. I do find it useful as a reminder that some things need checking.
I do not have a solution for the issue under point 1 above, though I do believe that it should be tackled by FamilySearch. All of us are bound by the same rules regarding the copyright, terms of use, etc. for the sources we use; as an example, I can't post images of digital copies of the extracts from the civil registers of births, marriages, and deaths from England and Wales (though I can transcribe and post the information contained in them).
We need:
a. a method for the Quality system to accept and act on self-cited sources while avoiding abuse of the system; this is evidently a bigger issue than the Quality system itself.
b. an accepted method for users to index a non-indexed source on FamilySearch; such a method evidently already exists but is not immediately accessible when citing a non-indexed source.
c. wider permissions to correct incorrectly-indexed sources (including permissions for people who are not at an FSC or affiliate library, and who do not have access to an image via FamilySearch but can access it elsewhere) or at least the ability to flag the index for review.
d. More generally there are entries (indexed or otherwise) which are incorrect and need annotating; an example is birth year/birth date errors, variant name spellings and errors of persons names and place names. The Quality system needs to take account of such annotations.
e. The Quality Score should not be treating as a mismatch certain errors such as: a calculated birth year from a census against an actual date or month-year date in a Birth entry. Given the frequency of calculated birth year being one-year off, I don't believe that one-year differences should lead to Quality Score degradation either.
1 -
Your many interesting points makes it difficult to drop out of this discussion.
Point 1: Some relevant sources are not available on FS. My ancestors were Quakers who kept excellent records -- almost none are on FS. But, FS has access to records on Ancestry. FS needs to do more in the Sources section to guide users to construct proper citations referencing sources so that the algorithm can find, read and extract the relevant information that is in those record and determine if that information is consistent with the profiled claims. But the algorithm should also be programmed to routinely review the original record and update or correct any mistakes resulting from earlier examinations.
Point C: wider permissions to correct incorrectly-indexed source
Sure, always appropriate to make corrections but the fundamental point is that derivative record are generally less reliable than the original sources of that record.
FS should guide users into recognizing the difference between an original source and the derivative offspring so that when the original source is found and properly cited all references to the extracted copies of tha toriginal source can be bracketed, denigrated and removed. Multiplecopies of an extracted index do not add value to the original source. We don't need an index to stand between the original record and the claim made in the details of the profile.
Point E: calculated birth years -- We frequently lack direct evidence for genealogical claims. American census records since 1850 show groups of people living in the same household and we infer that the children included in that group are biological children of the adult man and woman listed at the top of that group. Sometimes these inferences can be complex: even the claim that x and y were ever a couple can be shown only by reference to information extracted from 2-4 distinct documents spanning a 20 year period.
I doubt that the DQS can currently follow that sort of logical progression.
There is more trouble with calculating birth years -- the algorithm seems to have no comprehension of the distinction between the British Civil Julian and Gregorian Calendars. Benjamin Franklin LJLQ-WRC, the writer,statesman, scientist, inventor is given a date of birth of January 6,1706. Is this a British Julian date or a Gregorian date? -- Actually it's a hybrid date. He was born and baptized in Boston on January 6, 1705 British Julian which is equivalent to January 17, 1706 on the Gregorian Calendar. Will the algorithm recognize this?
Unfortunately it seems no document has survived that shows that January 6, 1705 date of birth. The earliest records of Boston births appear to be transcriptions from the later 18th century. --Some clerk converted his year of birth from 6 January 1705 to 6 January 1706-- one of the transcriptions seems to clearly show that the 06 part of 1706 was altered to 06. All the later printed and indexed transcriptions show this 1706 date. Fortunately, the original baptism record has survived even though it was also altered to show a date of birth as1706 and does not clearly display a 1705 date. But the addition of that 1706 date is in a different handwriting and was done in such a way as to preserve the original record. Looking at the entire list of baptisms over the years it is clear that the baptisms that follow those labeled for 1704 are the 1705 baptisms -- if they were 1706 Julian they were all on Mondays which is highly improbable. If those dates are interpreted as1706 Gregorian they were all on Wednesdays. Only if those dates are interpreted as 1705 Julian do those baptisms occur on Sundays.
We can hope that someday the algorithm will be able to follow this sort of reasoning.The current generation of AI can follow it but only if it is layed out very carefully so it understands that the new year is incremented differently on different versions of the Julian Calendar and that the British Civil Julian Calendar is not identical to the Historical Julian Calendar that was reformed in 1582 and that started each year on January 1.
1 -
I think that this is certainly legitimate, but for the foreseeable future I think we will have to accept that the algorithms used here will be able to handle typewritten text. So an index to enable access to the images is the first step.
For County Durham, England, we have good, accessible, bishop's transcripts available on the FamilySearch site. These are not indexed here yet, but have been indexed (mostly) on the Findmypast website. It makes looking for them quicker than working through the images of the microfilm.
Since there are transcriptions of many of the parish records already, it's actually not too difficult to find the correct Bishop's Transcript and check the image. It often contains extra information which was not originally noted when the indexes were made from the parish records, essentially the abode and the occupation of the father. For some parishes with chapels of rest it's useful to see the name of the officiating priest as well. All this is essential when disambiguating people with the same surnames and often even same forenames and approximate year of birth, but in different families at different named locations in the same area.
This is why I say we need to be able to transcribe/index images and attach them to the right people. The Quality Score system can help, but only if those with access to images (here or elsewhere) are able to update incorrect indexes and transcriptions and add those that are missing.
0 -
Oh, also, one point about derivative sources: the indexes to Bishop's Transcripts are of course transcriptions of transcriptions. The Bishop's Transcripts are transcriptions of the parish records, and these are in turn rewritings of the original notes that the priest made in many cases. You are lucky with the Quaker records; they were very carefully maintained I believe. My great(x3) -grandfather Francis Shield is found in the Quaker birth records of Allendale, as are his siblings.
The GRO England and Wales central civil Register of Births is a copy of the original Register Office record (though I hope they did not make any mistakes), and the lists we work from are transcriptions from those copies.
And then there are the fictitious fathers mentioned on some church marriage records (I have only come across one person who did not assert a father's name in his marriage register, and one who gives two different names in different marriages just to complicate things).
So, yes, of course, going to the original images is important, if rather difficult in many cases. It's a pity that Copyright, T&Cs and other conditions make it difficult to share images where needed.
0 -
Thank you for your feedback. There are some great points.
We continue to evolve the Quality Score, and we are working to polish the rough edges. We are working on some of the birth date issues.
Thanks again for your suggestions!0