AI is just a predictive algorithm

AI is just super predictive text and we can use it to give family history predictions. Just like forecasting the weather, it will be off sometimes. I was just asking AI chat bot perplexity this morning if there was a tool that can act as a fact checker to provide percentage of confidence between parents sets based on predefined criteria (such as linked names, location, birth age) and it said it did not exist. Then I found this data quality score which is very much a similar idea that flags inconsistencies and is based on algorithms all the same. I am in the position when many of my tree is filled in, yet come across two candidates as parents yet don't feel confident with what prior researchers have matched up, and would enjoy a tool that could give a score of one option over another. People sometimes just want to connect there family line to royalty somehow or put someone down instead of drawing a blank. If this tool could give me a confidence score based on evidence that goes from 99.99% confidence (DNA) to 98% based on birth certificate records with exact names matching, 95% based on bible lists and 90 names in census or other family records and so forth, all the way down to 50 40 or 30 percent for just having the same name and general birth window. A way to score confidence not just of having records attached to an individual, but also how relevant relevant that record is and how ambiguous a connection is and how well the joining of similar and strong evidences corroborate to prove or give more confidence to a connection. This is a job for AI and I think it for sure starts with this data quality score.
Comments
-
That's a very interesting angle (though '50 40 or 30 percent for just having the same name and general birth window' seems very high to me, especially for common surnames).
A couple of comments.
1.Other FS algorithms that are perhaps relevant here are the FT matching and record hinting algorithms, both of which provide lists of matches with attached confidence percentages.
2.AI's output is only ever going to be as good as the instructions/training you give it and the data you feed it. The data you mention is all in different places and formats (FS has no DNA information, the England and Wales BMD information held by FS is just indexes of registrations by quarter, etc.) The picture you paint could therefore only be delivered via a collaborative initiative, with providers and record custodians signing up to providing the necessary more detailed inputs and keeping them up to date (assuming unique identification/matching of the individuals concerned was possible, obviously).
What do others think?
0 -
I think that people need to keep in mind something that is demonstrated by the Data Quality Checker. All it can tell us is that the data is consistent. It cannot tell us whether the data is correct.
4 -
@trentcon Thanks for the suggestion!
We'd like to get to something along the lines of what you are suggesting. The Quality Score is probably a stepping stone along the way.0 -
@Mary Anna Ebert I would personally want to see FS get its own house more widely in order re Data Quality first - the current UI setup is a fantastic step forward, but the APIs used by third party solutions don't appear to have any access to DQ information as yet, and misguided automated bulk inserts (e.g. by the BYU Record Linking Lab, or big gedcom uploads) cause far more DQ trouble than any individual human editor ever could.
0 -
The Data Quality Checker, in my opinion, is not yet ready to be taken seriously. It cannot read and apply simple direct evidence effectively.
Probably the simplest test for the Data Quality Checker are the dates of birth and death. In the Vital Details Section of each profile we enter the name, date/place of birth and date/place of death. Sources are tagged as evidence to show that the facts we entered are actually true or at least consistent with the sources.
The Data Quality Checker apparently is designed to verify that the sources actually support or are at least consistent with the facts as we have entered them. But the Data Quality Checker cannot actually do this. It cannot detect when the sources are inconsistent with each other nor when they contradict and prove that the facts are false. It looks as if the Data Quality Checker can see that sources are provided but it cannot detect if there is actually any important relationship between those sources and they facts they supposedly reference.
Two examples might be anomalies but please take a look at the profile on Joseph Hewes, a signer of the Declaration of Independence, LCYM-ZXW.
Look in the Details Section on his Birth. The Data here is rated as High Quality. It says he was born on 23 June 1730. Three sources are referenced for that date of birth (actually 2 sources- two of them are identical). Both of those sources say Hewes was born on July 9, 1730. The sources contradict the facts they are supposed to confirm. If the Data Quality Checker cannot detect a difference between July 9 and June 23 can it detect anything important at all?
President George Washington KNDX-MKG was probably born in Virginia but his profile includes inconsistent sources that say he was born in Connecticut and say that he was born in Virginia. That's a contradiction that the Data Quality Checker does not appear to be able to recognize.
The Connecticut source is a low quality source and can be ignored. But it can't be ignored until it is recognized as a low quality source. For the Data Quality Checker to be of any worth it must be able to recognize that some sources are low quality sources, be able to discount the value of those sources and thus be able to resolve the contradiction between it and a higher quality source.
The Data Quality Checker is checking something but it does not seem to be entirely effective in checking for quality or consistency of the sources nor checking for consistency between sources and facts.
0 -
Unfortunately the two examples you are not really useful because they are both read only profiles and are missing a key feature. On regular profiles in the Research Help section there is a Show All link:
Clicking there brings you to the screen that lists all the active and all the dismissed items from the section.
I was recently working on a profile that did not have a high score for the birth information because the sources for his birth were indexed incorrectly in some of them and were just estimated years in others. Since I have a source that is his actual christening record and so know for certain that the later sources are just wrong, I dismissed all the data quality flags complaining about the difference in birth dates. After doing so, the rating went up to High. Here is the page for that individual that you cannot see on your two examples:
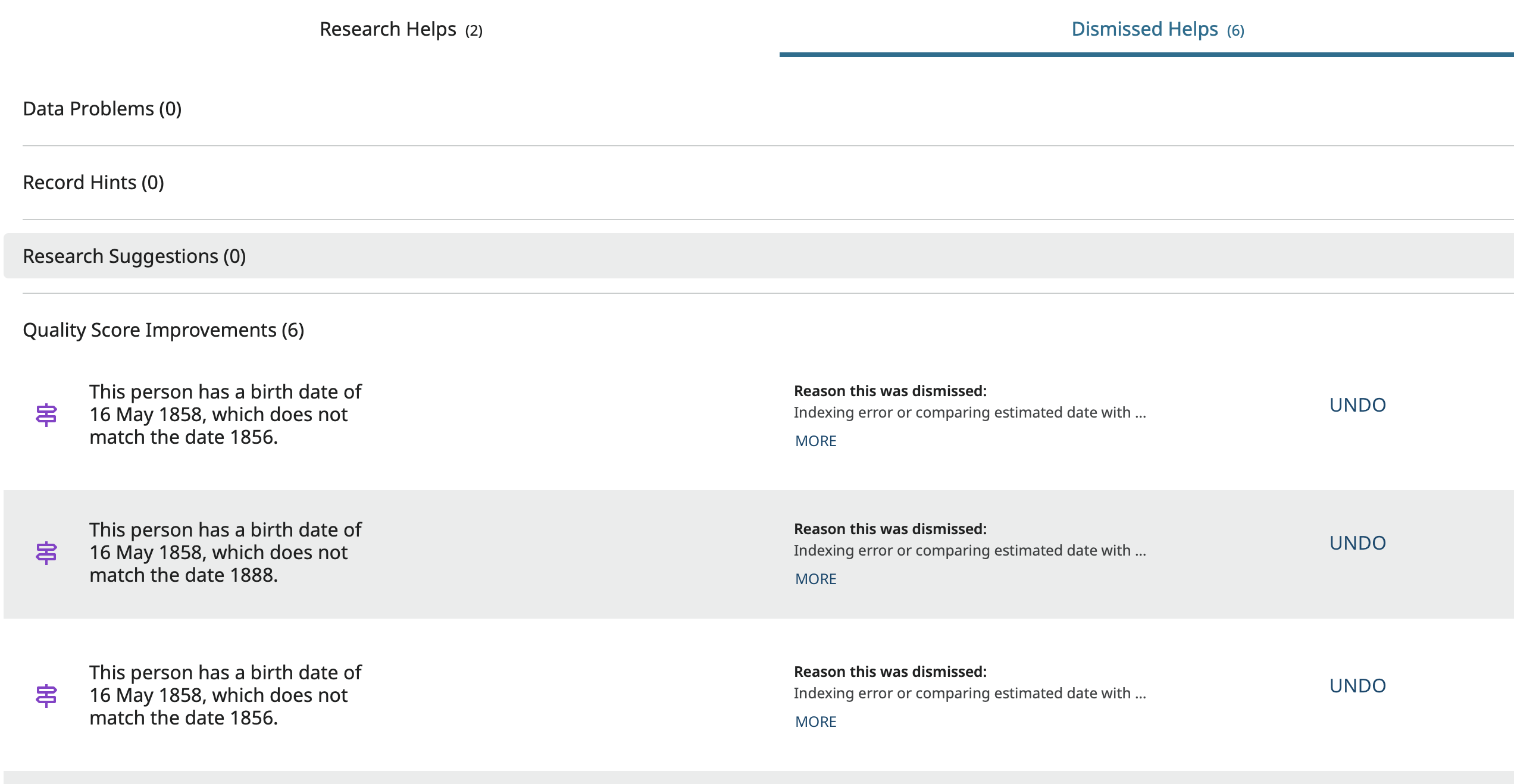
These flag dismissals show only here because they are research helps. They do not show up in the change log because dismissing them does not change anything on the profile.
Looking at your examples, FamilySearch was working on George Washington's profile in March 2025 and and on Joseph Hewes in April 2025. They may well have dismissed the data conflict flags for all the sources that had incorrect information. We have no way to check.
In my example, the data quality checker was doing exactly what it was supposed to do: Flag a difference between profile data and source data. Then I did what we are supposed to do. Evaluate the issue then either fix the profile which will result in the flag vanishing automatically or confirm the source is inaccurate and dismiss the flag manually.
0 -
Gordon — I appreciate the thoughtful feedback.
Your comments require me to revise my position: first I won't make any further efforts to raise the Data Quality Score on any profiles that I follow. You focus on inconsistent data. In the area where most of my research occurs (17th and 18th Century Quakers) just about every date prior to the adoption of the Gregorian Calendar in 1752 is screwed up.
I'm looking at David Cooper LZKB-712 ( one of the early Quaker abolitionists) with a birth record rated at low quality. Two different sources easily visible: one source has dob as 9 Feb 1724 another has his dob as 9 Dec 1724. His Quaker meeting recorded his birth as 9th of 12th month 1724/5. So by the modern calendar he was born on 20 February 1725— that's the way I've entered his dob.
The Quaker record is the best source available for his date of birth. It is equal, given the era in which he lived, to any birth certificate in evidentiary value.
But we cannot ignore the other derivative records that misinterpreted the date. Any computer program that is represented as qualified or able to check on the validity of birth facts should be programed to work this problem out. It should be able to spot the apparent but not real, inconsistency, identify that it is due to the difference in the Julian-Gregorian order of the months, realize there is no real inconsistency and spot whether or not the apparent inconsistency was resolved.
At the very very least it should be able to spot that 9 Feb 1724 and 9 Dec 1724 are a misinterpretations of 9 12th month 1724/25. There are existing algorithms devoted to converting Julian dates to Gregorian dates. The Quality Data Score algorithm should be able to spot a pre-1753 date and calculate the variations on it. There is only an apparent inconsistency. This is RELATIVELY simple stuff. AI is not required at this level.
My attitude is that the Quality Data Score is still in its earliest stage of development and it will improve.
With the help of your comments and of a couple of others, I have realized that at this stage I should pay no attention to the Data Quality Score for dates prior to 1752 or for sources that are not index — this probably involves post 1752 profiles as well but I'm not quite sure of that.
The sources that display apparently inconsistent data should not be removed.
0 -
I hope I was not misunderstood. I totally agree that "The sources that display apparently inconsistent data should not be removed." And I would never do that. What is important is to dismiss the data quality score flag and put in a good reason such as "Birth date on profile is a Gregorian date and the birth date in the source is a Julian date. These are actually the same date and there is no conflict."
Neither the programmers nor a future AI routine can learn in a vacuum. They need data. I would hope that at some point either of them would pull out a large sampling of dismiss flags, determine why the flags were dismissed, and use the information to improve the routine. The programmers are already doing this based on our posts here such as in this example:
Also, you will probably be interested to know that the Julian/Gregorian issue has been brought up previously:
Unfortunately that user never came back to give more information about where or when or how this was being an issue. It isn't a simple issue. For example, you mention 1753, but in Norway where I do most of my Family Tree work, the Julian calendar was used until 18 February 1700 and they switched to the Gregorian calendar on 1 March 1700. According to Wikipedia, Greece didn't adopt the Gregorian calendar until 1923. The designers of the Data Quality Score version 0.002 have a massive amount of work to do to account for the specific requirements of each time and place through history.
0 -
Yes -- I misunderstood you -- my fault -- I did not read your post carefully enough. I did not see how to "dismiss" a low quality score flag for date of birth -- I was looking in the Details Section only. -- Thanks for your persistance in trying to help me. I finally found it and I'll start using it. I frequently check with a calendar converter at this site: https://stevemorse.org/jcal/julian.html It has a dropdown list of when various countries and principalities adopted the Gregorian Calendar.
0 -
To what extent this is relevant on this thread, I'm not sure, but I feel the need to mention yet again, that the change in the first date of the new year from (an example) 25 March to 1 January did not necessarily take place in the same year as the change from the Julian to Gregorian calendar.
For instance, Scotland moved to 1 January as a New Year's Day on 1 January 1600 (new style), whereas England didn't do that until 1 January 1753 (new style).
So the contemporary records in Scotland would have seen 31 December 1599 followed by 1 January 1600, whereas contemporary records in England would have seen 31 December 1599 followed by 1 January 1599, which might then be dual dated in later transcripts as 1 January 1599/00.
Tracking not just the transition from Julian to Gregorian but also the change of New Year's Day is starting to get just a little much in my view. (Especially when you throw in those awkward customers who unilaterally moved to 1 January before everyone else did!)
1
